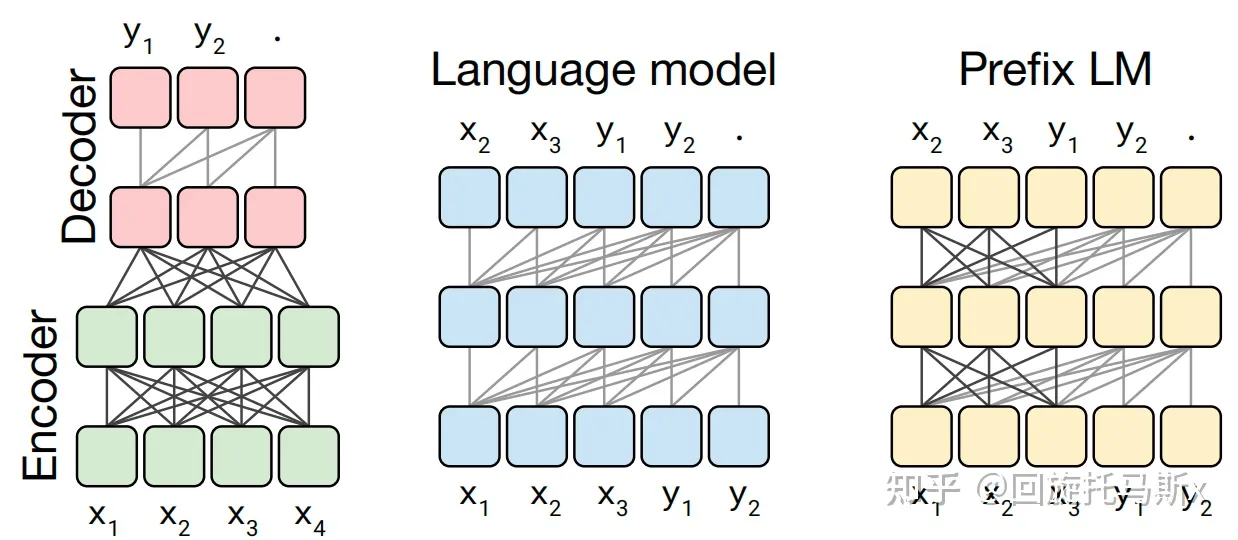
为了方便分析,先定义好一些数学符号。记 transformer 模型的层数为
模型参数量
self-attention 块的模型参数有
self-attention 块和 MLP 块各有一个 layer normalization,包含了2个可训练模型参数:缩放参数和平移参数,形状都是
总的,每个 transformer 层的参数量为
除此之外,词嵌入矩阵的参数量也较多,词向量维度通常等于隐藏层维度
关于位置编码,如果采用可训练式的位置编码,会有一些可训练模型参数,数量比较少。如果采用相对位置编码,例如RoPE和ALiBi,则不包含可训练的模型参数。我们忽略这部分参数。
综上,
2.1 训练过程中的显存占用分析
在训练神经网络的过程中,占用显存的大头主要分为四部分:模型参数、前向计算过程中产生的中间激活、后向传递计算得到的梯度、优化器状态。这里着重分析参数、梯度和优化器状态的显存占用,中间激活的显存占用后面会详细介绍。训练大模型时通常会采用 AdamW 优化器,并用混合精度训练来加速训练,基于这个前提分析显存占用。
在一次训练迭代中,每个可训练模型参数都会对应1个梯度,并对应2个优化器状态(Adam 优化器梯度的一阶动量和二阶动量)。设模型参数量为 Φ ,那么梯度的元素数量为 Φ ,AdamW 优化器的元素数量为 2Φ 。float16数据类型的元素占2个 bytes,float32数据类型的元素占4个 bytes。在混合精度训练中,会使用 float16的模型参数进行前向传递和后向传递,计算得到 float16的梯度;在优化器更新模型参数时,会使用 float32的优化器状态、float32的梯度、float32的模型参数来更新模型参数。因此,对于每个可训练模型参数,占用了
使用 AdamW 优化器和混合精度训练来训练参数量为 Φ 的大模型,模型参数、梯度和优化器状态占用的显存大小为
2.2 推理过程中的显存占用分析
在神经网络的推理阶段,没有优化器状态和梯度,也不需要保存中间激活。少了梯度、优化器状态、中间激活,模型推理阶段占用的显存要远小于训练阶段。模型推理阶段,占用显存的大头主要是模型参数,如果使用 float16来进行推理,推理阶段模型参数占用的显存大概是
计算量 FLOPs 估计
FLOPs,floating point operations,表示浮点数运算次数,衡量了计算量的大小。
对于,计算 AB 需要进行 n 次乘法运算和 n 次加法运算,共计 次浮点数运算,需要 的 FLOPs。对于 ,计算 AB 需要的浮点数运算次数为 。
在一次训练迭代中,假设输入数据的形状为
MLP 块的计算,计算公式如下;
因此,对于一个 l 层的 transformer 模型,输入数据形状为
计算量与参数量的关联
当隐藏维度
一次训练迭代包含了前向传递和后向传递,后向传递的计算量是前向传递的2倍。因此,前向传递 + 后向传递的系数 =1+2=3 。一次训练迭代中,对于每个 token,每个模型参数,需要进行 2*3=6 次浮点数运算。
一次前向传递中,对于每个 token,每个模型参数,进行2次浮点数计算。使用激活重计算技术来减少中间激活显存(下文会详细介绍)需要进行一次额外的前向传递,因此前向传递 + 后向传递 + 激活重计算的系数=1+2+1=4。使用激活重计算的一次训练迭代中,对于每个 token,每个模型参数,需要进行
中间激活值分析
除了模型参数、梯度、优化器状态外,占用显存的大头就是前向传递过程中计算得到的中间激活值了,需要保存中间激活以便在后向传递计算梯度时使用。这里的激活(activations)指的是:前向传递过程中计算得到的,并在后向传递过程中需要用到的所有张量。这里的激活不包含模型参数和优化器状态,但包含了 dropout 操作需要用到的 mask 矩阵。
大模型在训练过程中通常采用混合精度训练,中间激活值一般是 float16或者 bfloat16数据类型的。在分析中间激活的显存占用时,假设中间激活值是以 float16或 bfloat16数据格式来保存的,每个元素占了2个 bytes。唯一例外的是,dropout 操作的 mask 矩阵,每个元素只占1个 bytes。在下面的分析中,单位是 bytes,而不是元素个数。
每个 transformer 层需要保存的中间激活占用显存大小为34bsh+5bs^2a 。对于 l 层 transformer 模型,还有 embedding 层、最后的输出层。embedding 层不需要中间激活。总的而言,当隐藏维度 h 比较大,层数 l 较深时,这部分的中间激活是很少的,可以忽略。因此,对于 l 层 transformer 模型,中间激活占用的显存大小可以近似为
对比中间激活与模型参数的显存大小
在一次训练迭代中,模型参数(或梯度)占用的显存大小只与模型参数量和参数数据类型有关,与输入数据的大小是没有关系的。优化器状态占用的显存大小也是一样,与优化器类型有关,与模型参数量有关,但与输入数据的大小无关。而中间激活值与输入数据的大小(批次大小
GPT3的模型参数量为175B,占用的显存大小为
GPT3的序列长度 s 为 2048 。对比不同的批次大小 b 占用的中间激活:
当 b=1 时,中间激活占用显存为
当 b=64 时,中间激活占用显存为
当 b=128 时,中间激活占用显存为
可以看到随着批次大小 b 的增大,中间激活占用的显存远远超过了模型参数显存。通常会采用激活重计算技术来减少中间激活,理论上可以将中间激活显存从
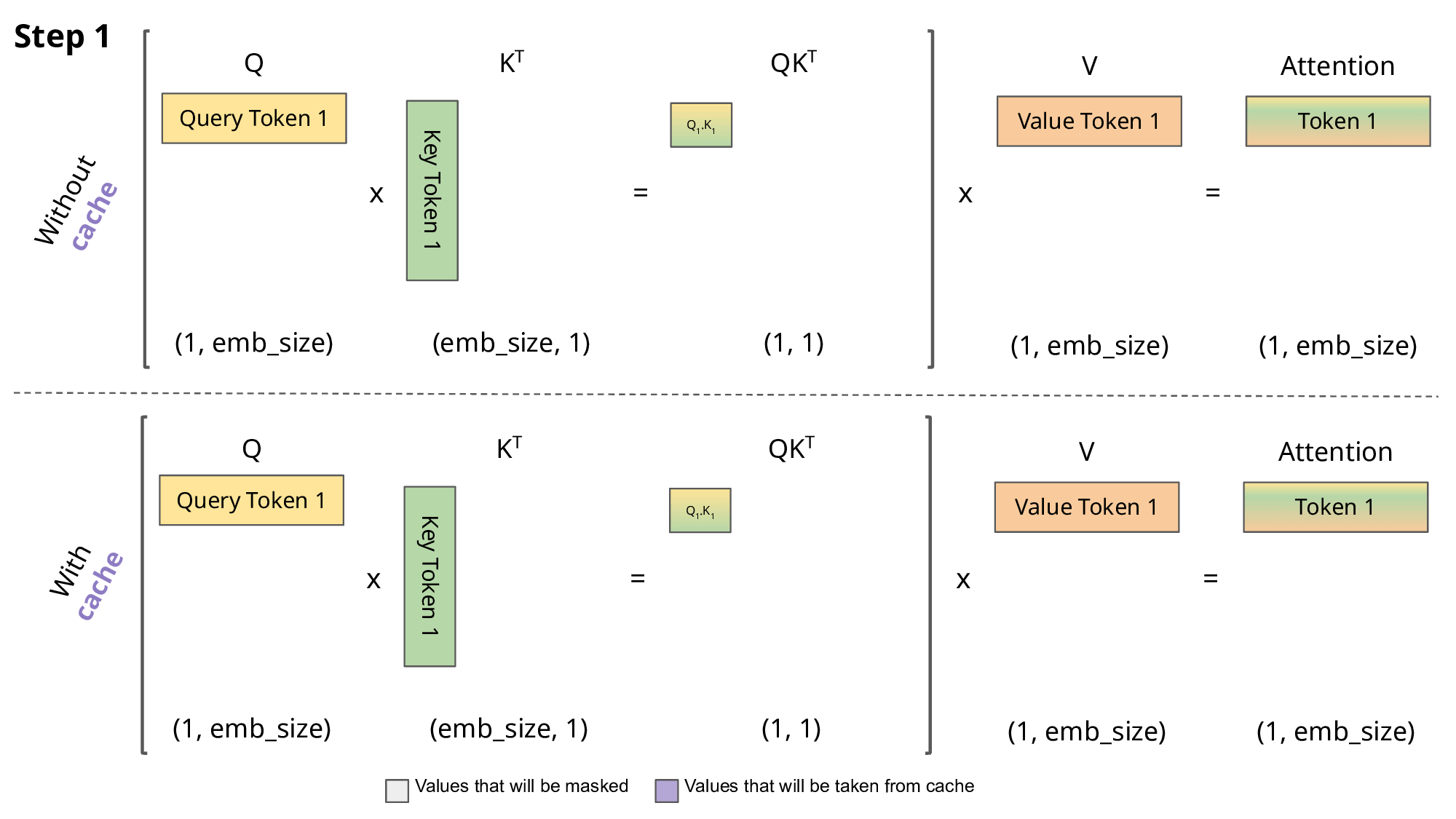
5. KV Cache
在推断阶段,transformer模型加速推断的一个常用策略就是使用 KV cache。一个典型的大模型生成式推断包含了两个阶段:
1. 预填充阶段:输入一个prompt序列,为每个transformer层生成 key cache和value cache(KV cache)。
2. 解码阶段:使用并更新 KV cache,一个接一个地生成词,当前生成的词依赖于之前已经生成的词。
5.1 KV Cache 的显存占用分析
第 i 个 transformer 层的权重矩阵为
预填充阶段
假设第 i 个 transformer 层的输入为
key cache和value cache的计算过程为:
第 i 个transformer层剩余的计算过程为:
解码阶段
给定当前生成词在第 i 个 transformer 层的向量表示为
更新key cache和value cache的计算过程如下:
第 i 个transformer层剩余的计算过程为:

5.1 KV Cache的显存占用分析
假设输入序列的长度为 s ,输出序列的长度为 n ,以 float16来保存 KV cache,那么KV cache 的峰值显存占用大小为
以 GPT3为例,对比 KV cache 与模型参数占用显存的大小。GPT3模型占用显存大小为350GB。假设批次大小 b=64 ,输入序列长度 s=512 ,输出序列长度 n=32 ,则 KV cache 占用显存为