原文: https://jia.je/hardware/2024/09/04/memory_model_and_memory_ordering/
决定访存的是否乱序,如何乱序,需要考虑:
- 从核内的视角来看,乱序执行不能修改程序的一样。实现乱序的性能,又要表现出类似串行的行为
- 从核间的视角来看,有一些指令不能乱序,否则会影响核间同步互斥的正确性
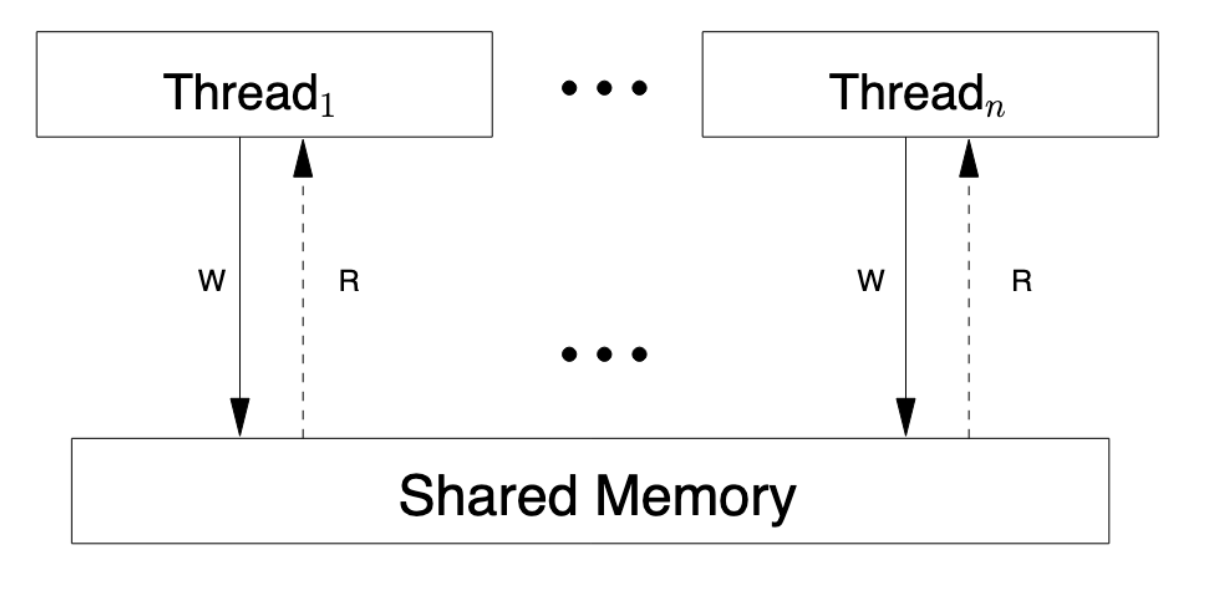
简单的内存模型 —— SC 模型
如果CPU 不做任何的乱序 -> program order == memory order
不同核心的访存序列到达内存子系统,同一个核心内的访存序列保持 program order。由于不同核心发起访存的时间不同,最后在内存子系统上执行的访存可能有这些情况:
- Ra Wa Rb Wb
- Ra Rb Wa Wb
- Ra Rb Wb Wa
- Rb Ra Wa Wb
- Rb Ra Wb Wa
- Rb Wb Ra Wa
Store Buffer
Store Buffer 是乱序执行 CPU 一个非常重要的优化,因为有些指令是有副作用的,不能够仅仅通过分支预测就让它执行,因此 CPU 对某些指令要求一定要做一次同步(即保证该在该指令之前的指令都已经完成了执行),那么这个指令就会一直阻塞,而若此时发生了缓存缺失,则会使得阻塞更加恶化。
为了解决这个问题,通常认为 Store 指令是不会失败的,因此可以放入一个队列里面,这个队列就称为 Store Buffer,Store Buffer 会保证指令按照顺序异步写入缓存,并且读需要同时读 Store Buffer
X86-TSO
依托 Store Buffer,我们可以构建出一个新的内存模型:在每个核心和内存子系统之间,多了一个 Store Buffer,Store 指令会先进入 Store Buffer,再进入内存子系统。当 Load 指令和 Store Buffer 中的 Store 指令有数据相关时,会从 Store Buffer 中取数据,如果不相关,或者不完全相关(例如只有一部分重合),则会从内存子系统中取数据,此时从内存子系统的角度来看,就发生了 Load 提前于 Store 执行的重排。这个模型被称为 X86-TSO
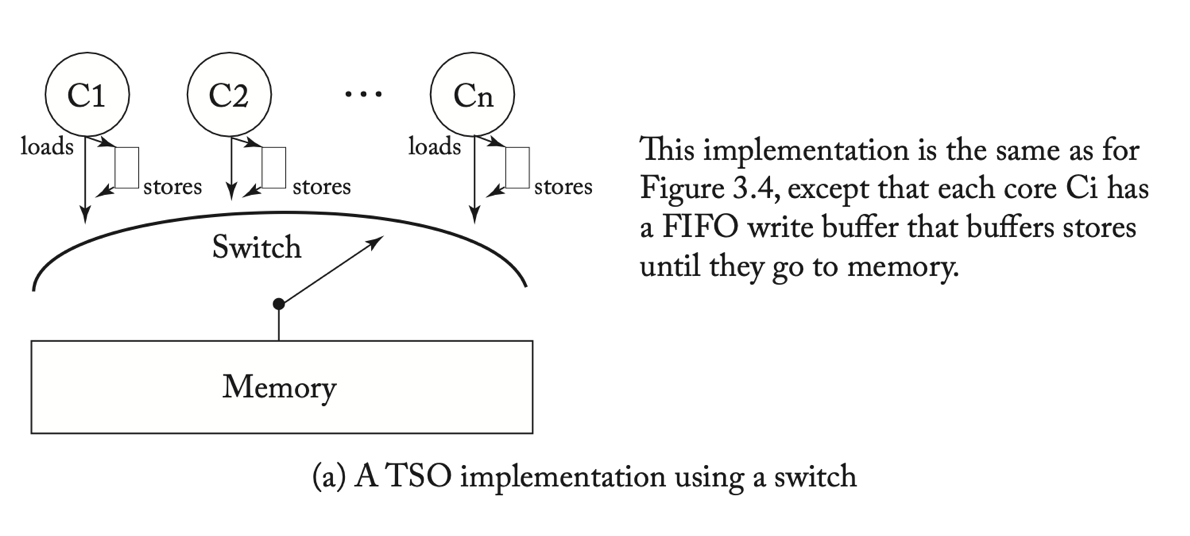
这里的 TSO 的全称是 Total Store Order,意思是针对 Store 指令(只有离开 Store Buffer 进入缓存的才算),有一个全局的顺序。内存子系统会处理来自不同核心的 Store,但会保证 Store 有一个先后顺序,并且所有核心会看到同一个顺序。
- 先 Load 后 Load:SC 和 X86-TSO 不允许重排
- 先 Load 后 Store:SC 和 X86-TSO 不允许重排
- 先 Store 后 Load:SC 不允许重排,X86-TSO 允许重排
- 先 Store 后 Store:SC 和 X86-TSO 不允许重
Weak/Relaxed Memory Model
在一些 X86 以外的指令集架构中(例如 ARM v8),有另外一种内存模型,一遍称为 Weak/Relaxed Memory Model。全都允许重排。如果用户不想重排,那再加合适的 fence 或 barrier 指令,阻止不想要的重排。在这个内存模型下,每个核心可以在向内存子系统读写前,对自己的读写进行重排
指令集会提供一些 fence 或者 barrier 指令来阻止各种类型的重排
- DMB:相当于 x86 的 mfence,保证 DMB 后的 Load 和 Store 不会重排到 DMB 之前,DMB 前的 Load 和 Store 也不会重排到 DMB 之后
- Load Acquire:对 Load 指令添加 Acquire 语义,保证 Load Acquire 之后的 Load/Store 不会被重排到 Load Acquire 之前
- Store Release:对 Release 指令添加 Release 语义,保证 Store Release 之前的 Load/Store 不会被重排到 Store Release 之后
不同的处理器和指令集使用了不同的内存模型,提供了不同的指令来控制乱序重排,但是对于软件开发者来说,会希望尽量用一套通用的 API 来控制乱序重排,可以兼容各种指令集,不用去记忆每个处理器用的是什么内存模型,不用去知道哪些指令可以用来解决哪些重排。
这个 API 在很多编程语言中都有,C 的 stdatomic.h,C++ 的 std::memory_order,Rust 的 std::sync::atomic::Ordering 等等。它们对各种处理器的内存序进行了进一步的抽象,并且在编译的时候,由编译器或标准库把这些抽象的内存序翻译成实际的指令。