SPDK 整体架构
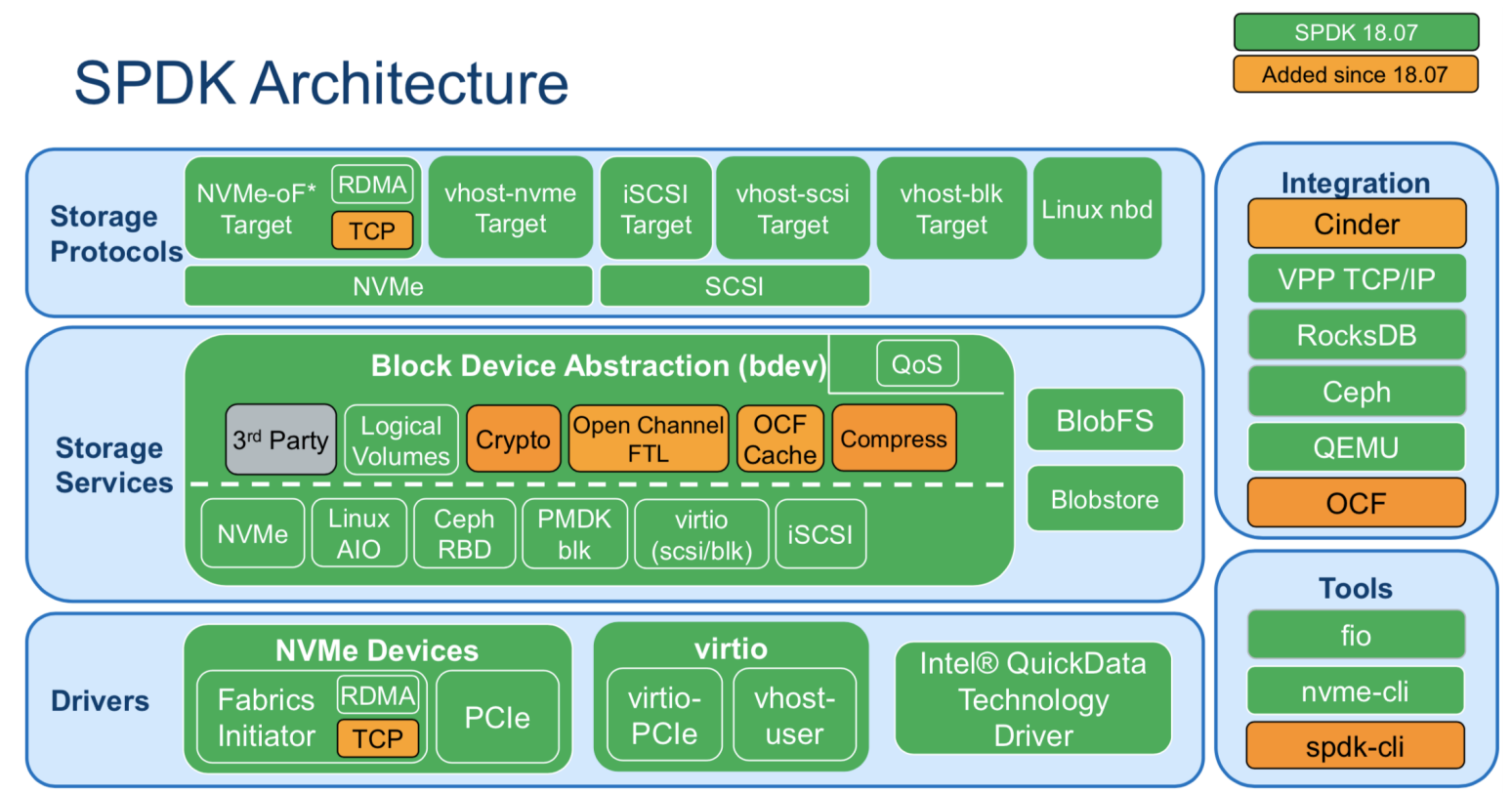
SPDK整体分为三层:
- 存储协议层(Storage Protocols),指SPDK支持存储应用类型。iSCSI Target对外提供iSCSI服务,用户可以将运行SPDK服务的主机当前标准的iSCSI存储设备来使用;vhost-scsi或vhost-blk对qemu提供后端存储服务,qemu可以基于SPDK提供的后端存储为虚拟机挂载virtio-scsi或virtio-blk磁盘;NVMF对外提供基于NVMe协议的存储服务端。注意,图中vhost-blk在spdk-18.04版本中已实现,后面我们主要基于此版本进行代码分析。
- 存储服务层(Storage Services),该层实现了对块和文件的抽象。目前来说,SPDK主要在块层实现了QoS特性,这一层整体上还是非常薄的。
- 驱动层(drivers),这一层实现了存储服务层定义的抽象接口,以对接不同的存储类型,如NVMe,RBD,virtio,aio等等。图中把驱动细分成两层,和块设备强相关的放到了存储服务层,而把和硬件强相关部分放到了驱动层。
SPDK 和传统 IO 栈对比
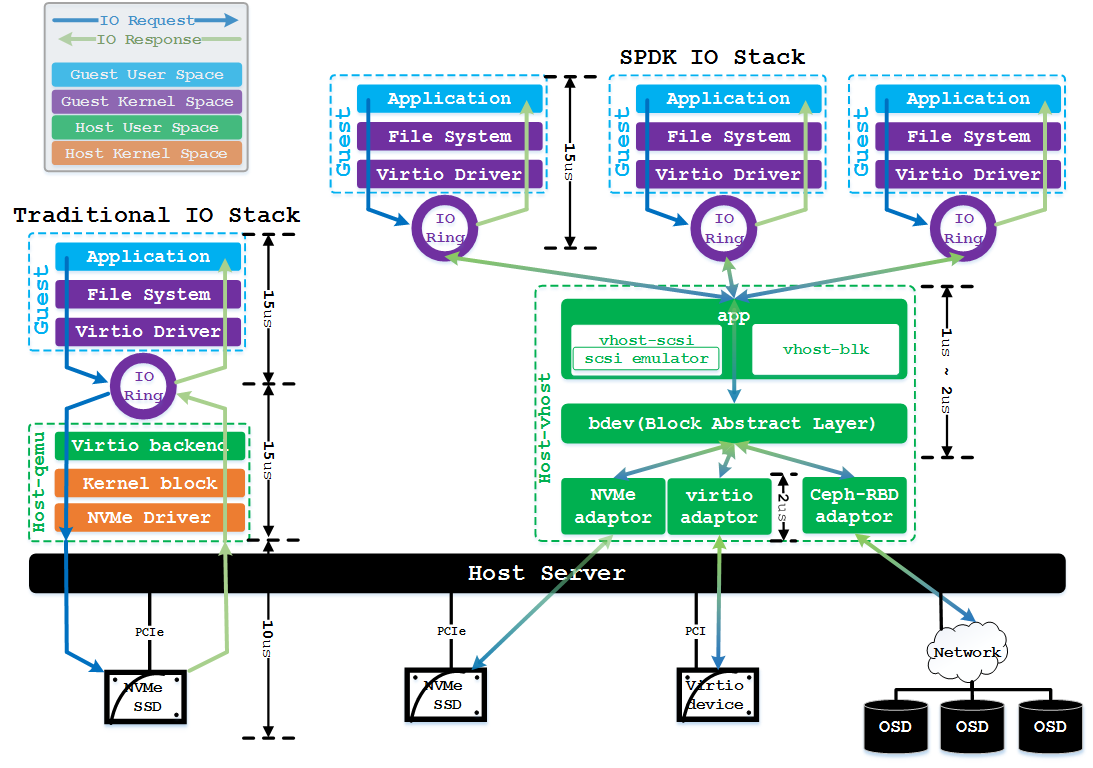
端到端时延对比来看,我们可以发现传统NVMe IO栈的总时延约40us,而SPDK用户态NVMe IO栈时延不到30us,时延上有25%以上的优化。另一方面,在吞吐量(IOPS)方面,如果我们给virtio-blk设备配置多队列(确保虚拟机IO压力足够),并在后端NVMe设备不成为瓶颈的前提下,传统NVMe IO栈在单个qemu io线程处理时,最多能达到20万IOPS,而SPDK vhost在单线程处理时可达100万IOPS,同等CPU开销下,吞吐量上有5倍以上的性能提升。
SPDK 线程模型
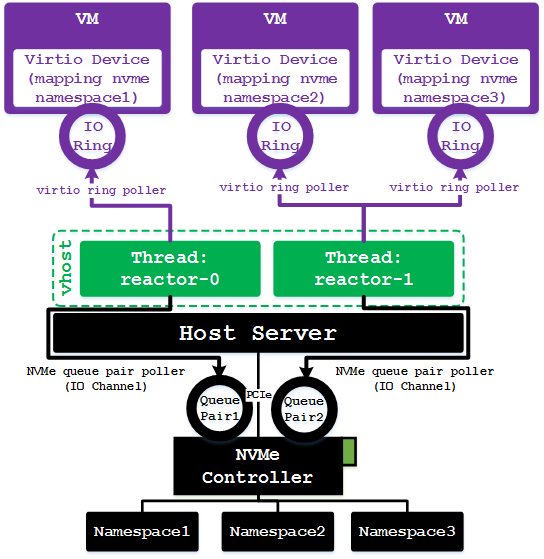
- 每个vhost线程都会轮循若干个vhost设备的IO环(一个vhost设备无论有多少个环,都只会在一个线程中处理),并且会向有操作述求的物理存储控制器(例如NVMe控制器、virtio-blk控制器、virtio-scsi控制器等)申请一个独立的IO Channel(IO环可以理解为对前端虚拟机呈现的一个IO Channel)并对其进行轮循。
- 论是前端虚拟机IO环,还是后端IO Channel,都只会在一个vhost线程中被轮循,因此这就避免了多线程并发操作同一个对象,可以通过无锁的方式操作IO环或IO Channel。