1. 字符串拼接
Go语言中,string是不可变的,拼接字符串事实上是创建了一个新的字符串对象
常见的拼接方式
- 使用
+
func plusConcat(n int, str string) string {
s := ""
for i := 0; i < n; i++ {
s += str
}
return s
}
- 使用
fmt.Sprintf
func sprintfConcat(n int, str string) string {
s := ""
for i := 0; i < n; i++ {
s = fmt.Sprintf("%s%s", s, str)
}
return s
}
- 使用
strings.Builder
func builderConcat(n int, str string) string {
var builder strings.Builder
for i := 0; i < n; i++ {
builder.WriteString(str)
}
return builder.String()
}
- 使用
[]byte
func byteConcat(n int, str string) string {
buf := new(bytes.Buffer)
for i := 0; i < n; i++ {
buf.WriteString(s)
}
return buf.String()
}
func preByteConcat(n int, str string) string {
buf := make([]byte, 0, n*len(str))
for i := 0; i < n; i++ {
buf = append(buf, str...)
}
return string(buf)
}
推荐的拼接方式
经过基准测试,使用 + 和 fmt.Sprintf 的效率是最低的,和其余的方式相比,性能相差约 1000 倍,而且消耗了超过 1000 倍的内存。strings.Builder、bytes.Buffer 和 []byte 的性能差距不大,而且消耗的内存也十分接近,性能最好且消耗内存最小的是 preByteConcat,这种方式预分配了内存,在字符串拼接的过程中,不需要进行字符串的拷贝,也不需要分配新的内存,因此性能最好,且内存消耗最小。
综合易用性和性能,一般推荐使用 strings.Builder 来拼接字符串。
这是 Go 官方对 strings.Builder 的解释:
A Builder is used to efficiently build a string using Write methods. It minimizes memory copying.
string.Builder 也提供了预分配内存的方式 Grow:
func builderConcat(n int, str string) string {
var builder strings.Builder
builder.Grow(n * len(str))
for i := 0; i < n; i++ {
builder.WriteString(str)
}
return builder.String()
}
性能差距背后的原理
- 主要在与内存分配的方式不一样,
+申请内存的时候是新生成一个字符串,空间大小为原来两个字符串的大小之和而strings.Builder,bytes.Buffer,包括切片[]byte的内存是以倍数申请的。例如,初始大小为 0,当第一次写入大小为 10 byte 的字符串时,则会申请大小为 16 byte 的内存(恰好大于 10 byte 的 2 的指数),第二次写入 10 byte 时,内存不够,则申请 32 byte 的内存,第三次写入内存足够,则不申请新的,以此类推。在实际过程中,超过一定大小,比如 2048 byte 后,申请策略上会有些许调整。我们可以通过打印builder.Cap()查看字符串拼接过程中,strings.Builder的内存申请过程。
func TestBuilderConcat(t *testing.T) {
var str = randomString(10)
var builder strings.Builder
cap := 0
for i := 0; i < 10000; i++ {
if builder.Cap() != cap {
fmt.Print(builder.Cap(), " ")
cap = builder.Cap()
}
builder.WriteString(str)
}
}
bytes.Buffer转化为字符串时重新申请了一块空间,存放生成的字符串变量,而strings.Builder直接将底层的[]byte转换成了字符串类型返回了回来。
- bytes.Buffer
func (b *Buffer) String() string {
if b == nil {
// Special case, useful in debugging.
return "<nil>"
}
return string(b.buf[b.off:])
}
- strings.Builder
// String returns the accumulated string.
func (b *Builder) String() string {
return *(*string)(unsafe.Pointer(&b.buf))
}
2. 切片的性能与陷阱
数组的长度是固定的,长度是数组类型的一部分。长度不同的 2 个数组是不可以相互赋值的,因为这 2 个数组属于不同的类型。例如下面的代码是不合法的:
a := [3]int{1, 2, 3}
b := [4]int{2, 4, 5, 6}
a = b // cannot use b (type [4]int) as type [3]int in assignment
在 C 语言中,数组变量是指向第一个元素的指针,但是 Go 语言中并不是。Go 语言中,数组变量属于值类型(value type),因此当一个数组变量被赋值或者传递时,实际上会复制整个数组。例如,将 a 赋值给 b,修改 a 中的元素并不会改变 b 中的元素:
a := [...]int{1, 2, 3} // ... 会自动计算数组长度
b := a
a[0] = 100
fmt.Println(a, b) // [100 2 3] [1 2 3]
为了避免复制数组,一般会传递指向数组的指针。
数组固定长度,缺少灵活性,大部分场景下会选择使用基于数组构建的功能更强大,使用更便利的切片类型。
切片使用字面量初始化时和数组很像,但是不需要指定长度:
languages := []string{"Go", "Python", "C"}
// or using func make([]T, len, cap) []T
// len是切片的长度,cap是切片的容量
languages := make([]string, 3. 3)
容量是当前切片已经预分配的内存能够容纳的元素个数,如果往切片中不断地增加新的元素。如果超过了当前切片的容量,就需要分配新的内存,并将当前切片所有的元素拷贝到新的内存块上。因此为了减少内存的拷贝次数,容量在比较小的时候,一般是以 2 的倍数扩大的,例如 2 4 8 16 …,当达到 2048 时,会采取新的策略,避免申请内存过大,导致浪费。
切片操作并不复制切片指向的元素,创建一个新的切片会复用原来切片的底层数组,因此切片操作是非常高效的。下面的例子展示了这个过程:
nums := make([]int, 0, 8)
nums = append(nums, 1, 2, 3, 4, 5)
nums2 := nums[2:4]
printLenCap(nums) // len: 5, cap: 8 [1 2 3 4 5]
printLenCap(nums2) // len: 2, cap: 6 [3 4]
nums2 = append(nums2, 50, 60)
printLenCap(nums) // len: 5, cap: 8 [1 2 3 4 50]
printLenCap(nums2) // len: 4, cap: 6 [3 4 50 60]
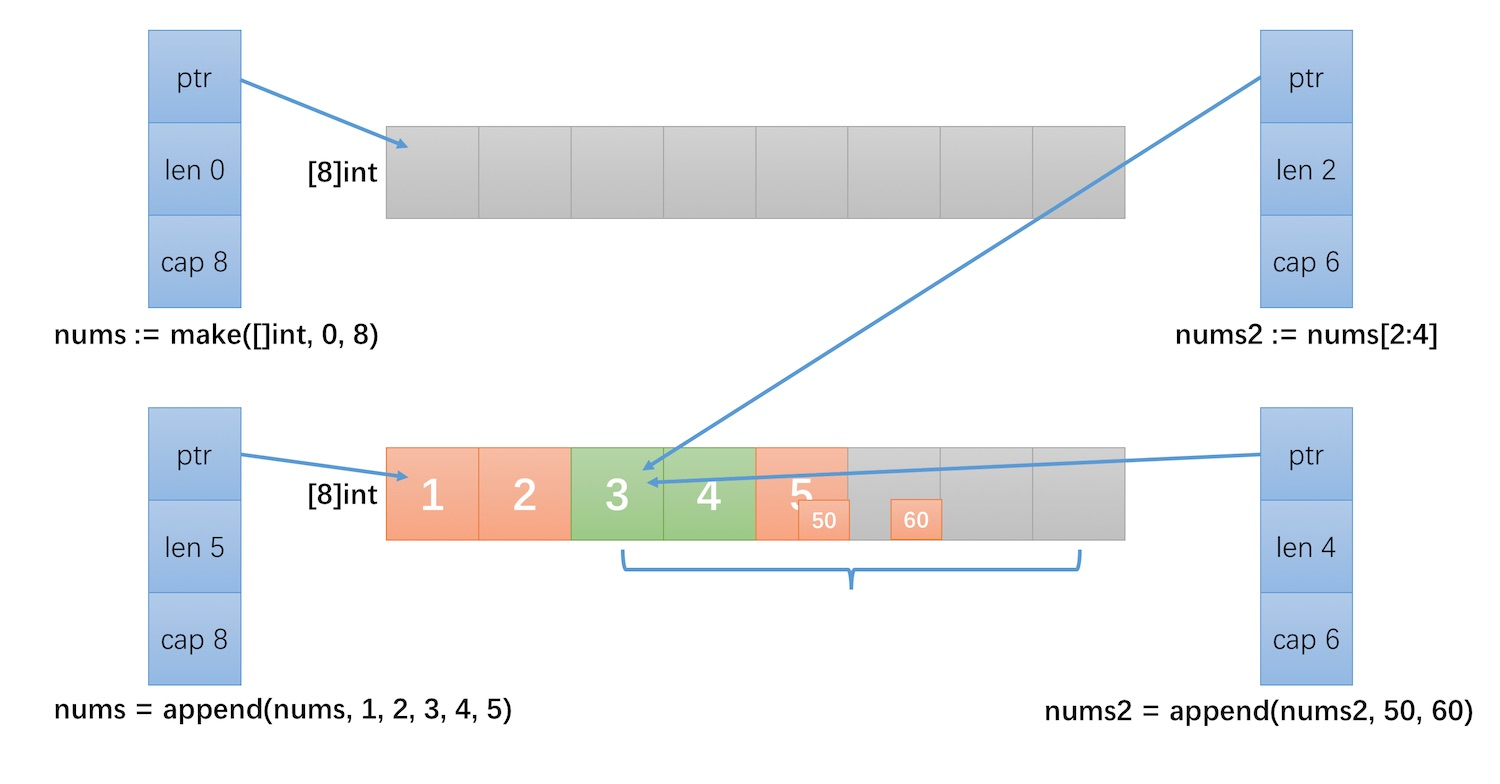
切片操作( Go Slice Tricks Cheat Sheet)
Copy
b = make([]T, len(a))
copy(b, a)
// or
b = append([]T(nil), a...)
Append
a = append(a, b...)
切片有三个属性,指针(ptr)、长度(len) 和容量(cap)。append 时有两种场景:
- 当 append 之后的长度小于等于 cap,将会直接利用原底层数组剩余的空间。
- 当 append 后的长度大于 cap 时,则会分配一块更大的区域来容纳新的底层数组。
因此,为了避免内存发生拷贝,如果能够知道最终的切片的大小,预先设置 cap 的值能够获得最好的性能。
Delete
a = append(a[:i], a[i+1]...)
Delete(GC)
if i < len(a)-1 {
copy(a[i:], a[i+1:])
}
a[len(a)-1] = nil
a = a[:len(a)-1]
Insert
a = append(a[:i], append([]T{x}, a[i:]...)...)
Filter(in place)
n := 0
for _, x := range a {
if keep(x) {
a[n] = x
n++
}
}
a = a[:n]
Push
a = append(a, x)
Push Front
a = append([]T{x}, a...)
Pop
x, a = a[len(a)-1], a[:len(a)-1]
Pop front
x, a = a[0], a[1:]
头部删除元素,如果使用切片方式,复杂度为 O(1)。但是需要注意的是,底层数组没有发生改变,第 0 个位置的内存仍旧没有释放。如果有大量这样的操作,头部的内存会一直被占用。
性能陷阱
-
大量内存得不到释放:在已有切片的基础上进行切片,不会创建新的底层数组。因为原来的底层数组没有发生变化,内存会一直占用,直到没有变量引用该数组。因此很可能出现这么一种情况,原切片由大量的元素构成,但是我们在原切片的基础上切片,虽然只使用了很小一段,但底层数组在内存中仍然占据了大量空间,得不到释放。比较推荐的做法,使用
copy替代re-slice
func lastNumsBySlice(origin []int) []int {
return origin[len(origin)-2:]
}
func lastNumsByCopy(origin []int) []int {
result := make([]int, 2)
copy(result, origin[len(origin)-2:])
return result
}
## 3. for和range的性能
### array/slice
```go
words := []string{"Go", "语言", "高性能", "编程"}
for i, s := range words {
words = append(words, "test")
fmt.Println(i, s)
}
- 变量 words 在循环开始前,仅会计算一次,如果在循环中修改切片的长度不会改变本次循环的次数。
- 迭代过程中,每次迭代的下标和值被赋值给变量 i 和 s,第二个参数 s 是可选的。
- 针对 nil 切片,迭代次数为 0。
Map
m := map[string]int{
"one": 1,
"two": 2,
"three": 3,
}
for k, v := range m {
delete(m, "two")
m["four"] = 4
fmt.Printf("%v: %v\n", k, v)
}
- 和切片不同的是,迭代过程中,删除还未迭代到的键值对,则该键值对不会被迭代。
- 在迭代过程中,如果创建新的键值对,那么新增键值对,可能被迭代,也可能不会被迭代。
- 针对 nil 字典,迭代次数为 0
Channel
ch := make(chan string)
go func() {
ch <- "Go"
ch <- "语言"
ch <- "高性能"
ch <- "编程"
close(ch)
}()
for n := range ch {
fmt.Println(n)
}
- 发送给信道(channel) 的值可以使用 for 循环迭代,直到信道被关闭。
- 如果是 nil 信道,循环将永远阻塞。
For和range的性能比较
- []int
func generateWithCap(n int) []int {
rand.Seed(time.Now().UnixNano())
nums := make([]int, 0, n)
for i := 0; i < n; i++ {
nums = append(nums, rand.Int())
}
return nums
}
func BenchmarkForIntSlice(b *testing.B) {
nums := generateWithCap(1024 * 1024)
for i := 0; i < b.N; i++ {
len := len(nums)
var tmp int
for k := 0; k < len; k++ {
tmp = nums[k]
}
_ = tmp
}
}
func BenchmarkRangeIntSlice(b *testing.B) {
nums := generateWithCap(1024 * 1024)
for i := 0; i < b.N; i++ {
var tmp int
for _, num := range nums {
tmp = num
}
_ = tmp
}
}
运行结果如下:
$ go test -bench=IntSlice$ .
goos: darwin
goarch: amd64
pkg: example/hpg-range
BenchmarkForIntSlice-8 3603 324512 ns/op
BenchmarkRangeIntSlice-8 3591 322744 ns/op
-
generateWithCap用于生成长度为 n 元素类型为 int 的切片。 -
从最终的结果可以看到,遍历 []int 类型的切片,for 与 range 性能几乎没有区别。
-
[]struct
type Item struct {
id int
val [4096]byte
}
func BenchmarkForStruct(b *testing.B) {
var items [1024]Item
for i := 0; i < b.N; i++ {
length := len(items)
var tmp int
for k := 0; k < length; k++ {
tmp = items[k].id
}
_ = tmp
}
}
func BenchmarkRangeIndexStruct(b *testing.B) {
var items [1024]Item
for i := 0; i < b.N; i++ {
var tmp int
for k := range items {
tmp = items[k].id
}
_ = tmp
}
}
func BenchmarkRangeStruct(b *testing.B) {
var items [1024]Item
for i := 0; i < b.N; i++ {
var tmp int
for _, item := range items {
tmp = item.id
}
_ = tmp
}
}
Benchmark的结果:
$ go test -bench=Struct$ .
goos: darwin
goarch: amd64
pkg: example/hpg-range
BenchmarkForStruct-8 3769580 324 ns/op
BenchmarkRangeIndexStruct-8 3597555 330 ns/op
BenchmarkRangeStruct-8 2194 467411 ns/op
- 仅遍历下标的情况下,for 和 range 的性能几乎是一样的。
items的每一个元素的类型是一个结构体类型Item,Item由两个字段构成,一个类型是 int,一个是类型是[4096]byte,也就是说每个Item实例需要申请约 4KB 的内存。- 在这个例子中,for 的性能大约是 range (同时遍历下标和值) 的 2000 倍。
与 for 不同的是,range 对每个迭代值都创建了一个拷贝。因此如果每次迭代的值内存占用很小的情况下,for 和 range 的性能几乎没有差异,但是如果每个迭代值内存占用很大,例如上面的例子中,每个结构体需要占据 4KB 的内存,这种情况下差距就非常明显了。
- []*struct{}
func generateItems(n int) []*Item {
items := make([]*Item, 0, n)
for i := 0; i < n; i++ {
items = append(items, &Item{id: i})
}
return items
}
func BenchmarkForPointer(b *testing.B) {
items := generateItems(1024)
for i := 0; i < b.N; i++ {
length := len(items)
var tmp int
for k := 0; k < length; k++ {
tmp = items[k].id
}
_ = tmp
}
}
func BenchmarkRangePointer(b *testing.B) {
items := generateItems(1024)
for i := 0; i < b.N; i++ {
var tmp int
for _, item := range items {
tmp = item.id
}
_ = tmp
}
}
运行结果:
goos: darwin
goarch: amd64
pkg: example/hpg-range
BenchmarkForPointer-8 271279 4160 ns/op
BenchmarkRangePointer-8 264068 4194 ns/op
切片元素从结构体 Item 替换为指针 *Item 后,for 和 range 的性能几乎是一样的。range 在迭代过程中返回的是迭代值的拷贝,如果每次迭代的元素的内存占用很低,那么 for 和 range 的性能几乎是一样,例如 []int。但是如果迭代的元素内存占用较高,例如一个包含很多属性的 struct 结构体,那么 for 的性能将显著地高于 range,有时候甚至会有上千倍的性能差异。对于这种场景,建议使用 for,如果使用 range,建议只迭代下标,通过下标访问迭代值,这种使用方式和 for 就没有区别了。如果想使用 range 同时迭代下标和值,则需要将切片/数组的元素改为指针,才能不影响性能。
3. 反射(reflect)性能
标准库 reflect 为 Go 语言提供了运行时动态获取对象的类型和值以及动态创建对象的能力。反射可以帮助抽象和简化代码,提高开发效率。
毫无疑问的是,反射会增加额外的代码指令,对性能肯定会产生影响的。
创建对象
通过反射创建对象的耗时约为 new 的 1.5 倍,相差不是特别大。
修改字段的值
对于一个普通的拥有 4 个字段的结构体 Config 来说,使用反射给每个字段赋值,相比直接赋值,性能劣化约 100 - 1000 倍。其中,FieldByName 的性能相比 Field 劣化 10 倍。
在反射的内部,字段是按顺序存储的,因此按照下标访问查询效率为 O(1),而按照 Name 访问,则需要遍历所有字段,查询效率为 O(N)。结构体所包含的字段(包括方法)越多,那么两者之间的效率差距则越大。
如何提高性能
- 避免使用反射(标准库中的json序列化和反序列化是用反射实现的)
- 使用缓存(避免使用
FieldByName,可以利用index和字典将name缓存起来)
空结构体的作用
因为空结构体不占据内存空间,因此被广泛作为各种场景下的占位符使用。一是节省资源,二是空结构体本身就具备很强的语义,即这里不需要任何值,仅作为占位符。
实现集合
Go 语言标准库没有提供 Set 的实现,通常使用 map 来代替。事实上,对于集合来说,只需要 map 的键,而不需要值。即使是将值设置为 bool 类型,也会多占据 1 个字节,那假设 map 中有一百万条数据,就会浪费 1MB 的空间。
因此呢,将 map 作为集合(Set)使用时,可以将值类型定义为空结构体,仅作为占位符使用即可。
type Set map[string]struct{}
func (s Set) Has(key string) bool {
_, ok := s[key]
return ok
}
func (s Set) Add(key string) {
s[key] = struct{}{}
}
func (s Set) Delete(key string) {
delete(s, key)
}
func main() {
s := make(Set)
s.Add("Tom")
s.Add("Sam")
fmt.Println(s.Has("Tom"))
fmt.Println(s.Has("Jack"))
}
不发送数据的信道(channel)(仅用于协同)
func worker(ch chan struct{}) {
<-ch
fmt.Println("do something")
close(ch)
}
func main() {
ch := make(chan struct{})
go worker(ch)
ch <- struct{}{}
}
仅包含方法的结构体
type Door struct{}
func (d Door) Open() {
fmt.Println("Open the door")
}
func (d Door) Close() {
fmt.Println("Close the door")
}