原文: https://strikefreedom.top/archives/linux-io-stack-and-zero-copy
计算机存储设备
- 磁盘和主存相比,每个二进制位的成本低了两个数量级,访问速度比主存慢了大概三个数量级
- 主内存是操作系统进行 I/O 操作的重中之重,绝大部分的工作都是在用户进程和内核的内存缓冲区里完成的。
RAM
MMU负责硬件实现从虚拟地址到物理地址的映射,这个映射是存在页表中的,页表除了映射关系外,还有一些控制位,可以实现权限管理或者其他的功能(例如缺页中断和Copy-on-Write)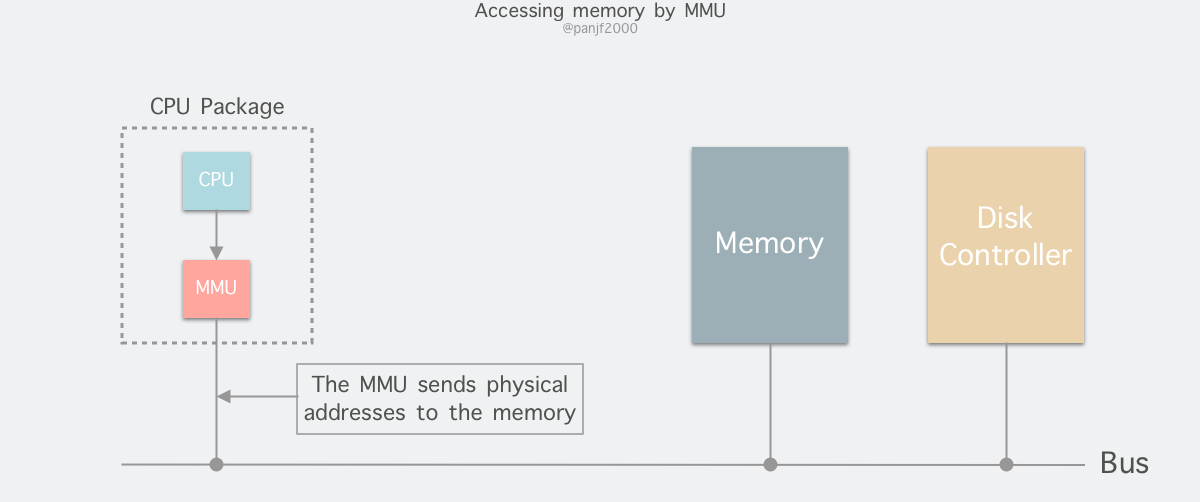
TLB 快表
页表一般是保存内存中的一块固定的存储区,导致进程通过 MMU 访问内存比直接访问内存多了一次内存访问,性能至少下降一半。TLB 可以简单地理解成页表的高速缓存,保存了最高频被访问的页表项,由于一般是硬件实现的,因此速度极快。
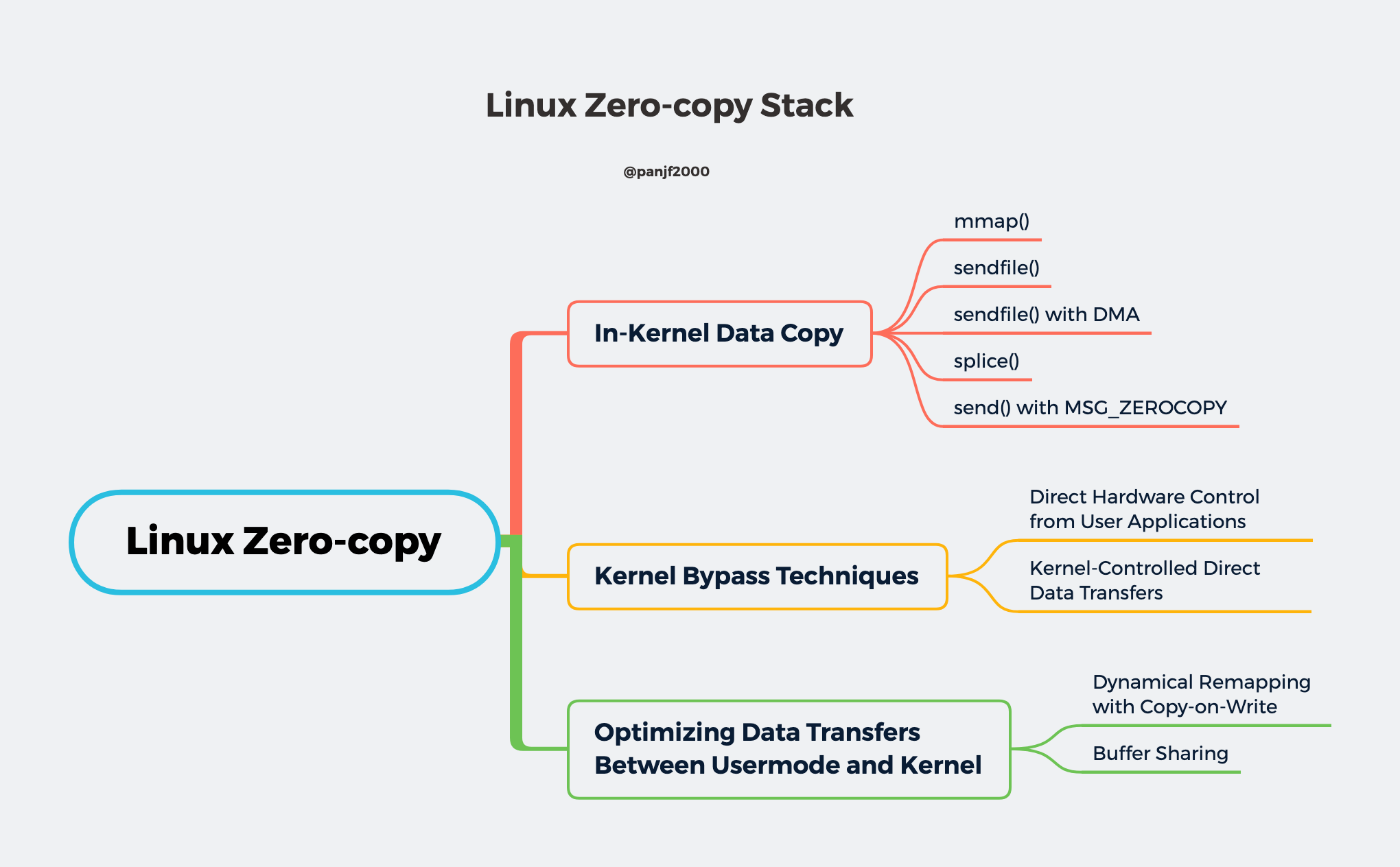
Zero-copy 优化
Zero-copy 的实现技术按照其核心思想可以归纳成大致的一下三类:
- 内核内数据拷贝:主要目标是减少甚至避免用户空间和内核空间之间的数据拷贝。在一些场景下,用户进程在数据传输过程中并不需要对数据进行访问和处理,那么数据在 Linux 的 page cache 和用户进程的缓冲区之间的数据传输就完全可以避免,让数据拷贝完全在内核里进行,甚至可以通过更巧妙的方式避免在内核里的数据拷贝。这一类实现一般是通过增加新的系统调用来完成的,比如 Linux 中的
mmap()、sendfile()、splice()和copy_file_range()等。 - 绕过内核的直接 I/O(kernel bypass):允许在用户态进程绕过内核直接和硬件进行数据传输,内核在传输过程中只负责一些管理和辅助的工作。这种方式其实和第一种有点类似,也是试图避免用户空间和内核空间之间的数据传输,只是第一种方式是把数据传输过程放在内核态完成,而这种方式则是直接绕过内核和硬件通信,效果类似但原理完全不同。
- 内核态和用户态之间的传输优化:这种方式侧重于在用户进程的缓冲区和操作系统的页缓存之间的 CPU 拷贝的优化,通过一些手段如 Copy-on-Write —— 减少用户空间和内核空间之间的数据复制、Buffer pool —— 通过回收和重用 buffer 降低内存分配的频次。这种方法延续了以往那种传统的通信方式,但性能上会更高效。
内核内数据拷贝
考虑把本地文件发送到互联网的流程
通用 I/O 流程
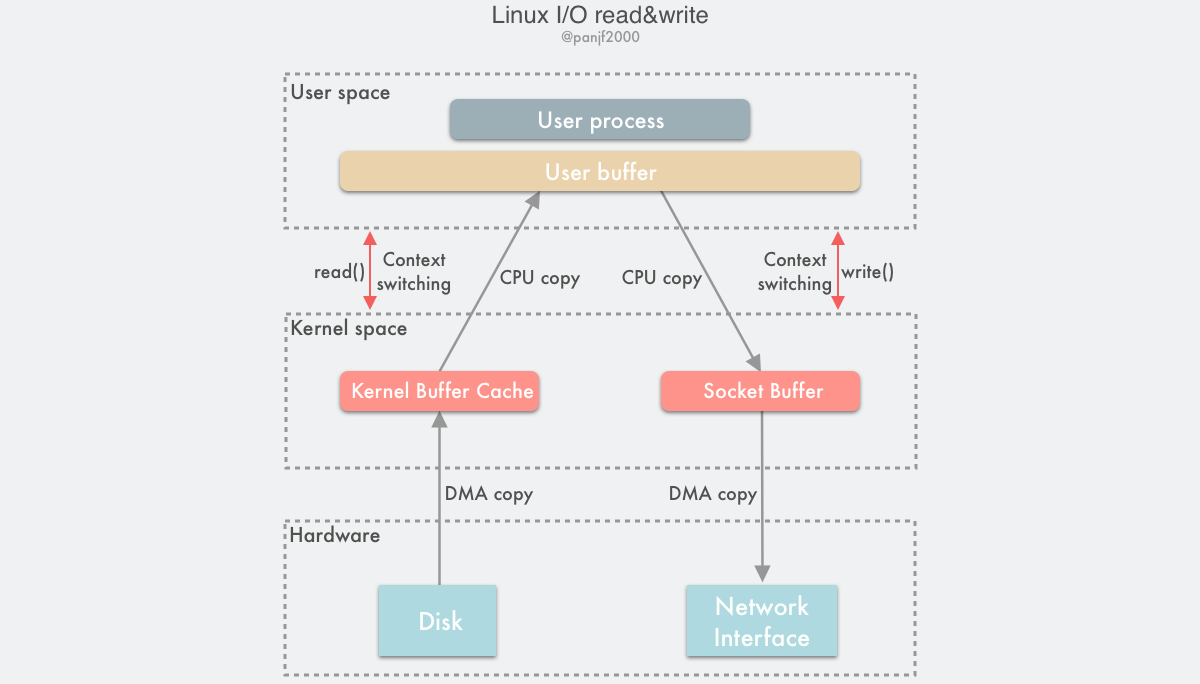
- 用户进程调用
read()系统调用,从用户态陷入内核态; - DMA 控制器将数据从硬盘拷贝到内核缓冲区,同时对 CPU 发出一个中断信号;
- CPU 收到中断信号之后启动中断程序把数据从内核空间的缓冲区复制到用户空间的缓冲区;
read()系统调用返回,上下文从内核态切换回用户态;- 用户进程调用
write()系统调用,再一次从用户态陷入内核态; - CPU 将用户空间的缓冲区上的数据复制到内核空间的缓冲区,同时触发 DMA 控制器;
- DMA 将内核空间的缓冲区上的数据复制到网卡;
write()返回,上下文从内核态切换回用户态。
一共触发了 4 次用户态和内核态的上下文切换,分别是 read() / write() 调用和返回时的切换,2 次 DMA 拷贝,2 次 CPU 拷贝,加起来一共 4 次拷贝操作。
mmap () 替换 read ()
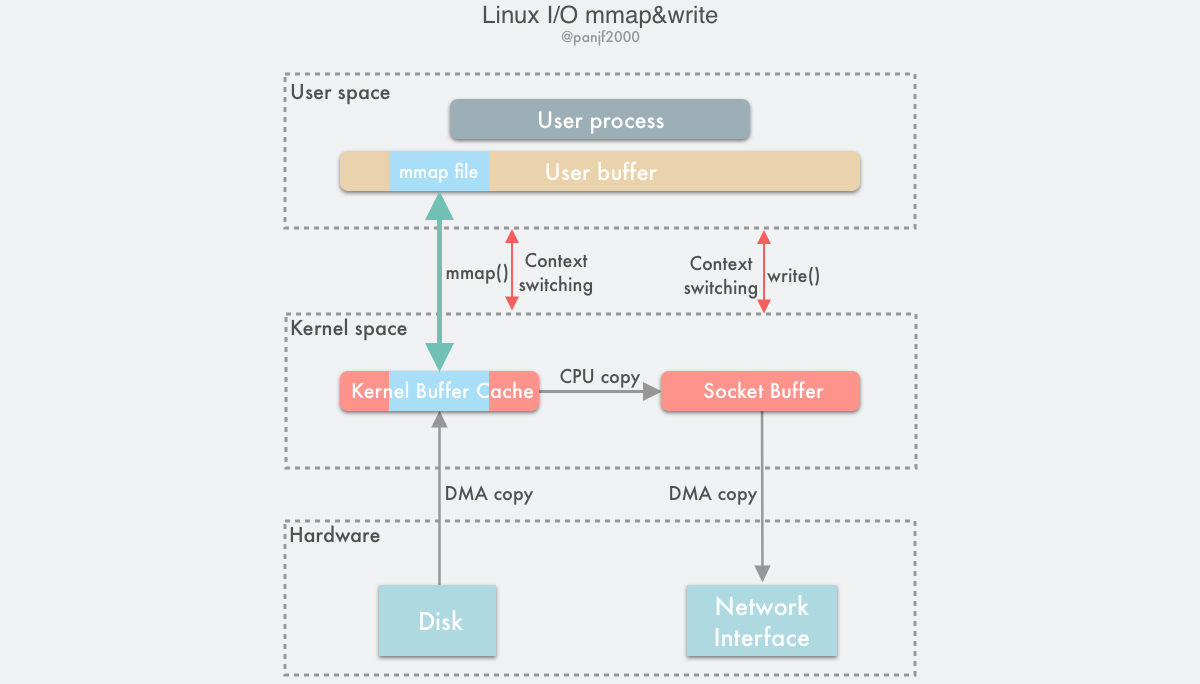
- 用户进程调用
mmap(),从用户态陷入内核态,将内核缓冲区映射到用户缓存区; - DMA 控制器将数据从硬盘拷贝到内核缓冲区;
mmap()返回,上下文从内核态切换回用户态;- 用户进程调用
write(),尝试把文件数据写到内核里的套接字缓冲区,再次陷入内核态; - CPU 将内核缓冲区中的数据拷贝到的套接字缓冲区;
- DMA 控制器将数据从套接字缓冲区拷贝到网卡完成数据传输;
write()返回,上下文从内核态切换回用户态。
优点:
- 节省物理内存空间
- 省去了一次 CPU 拷贝
缺点:
- 内存映射是一个开销很大的虚拟存储操作:它需要修改页表以及使用内核缓冲区内的文件数据淘汰掉当前 TLB 里的缓存以维持虚拟内存映射的一致性
sendfile() 系统调用
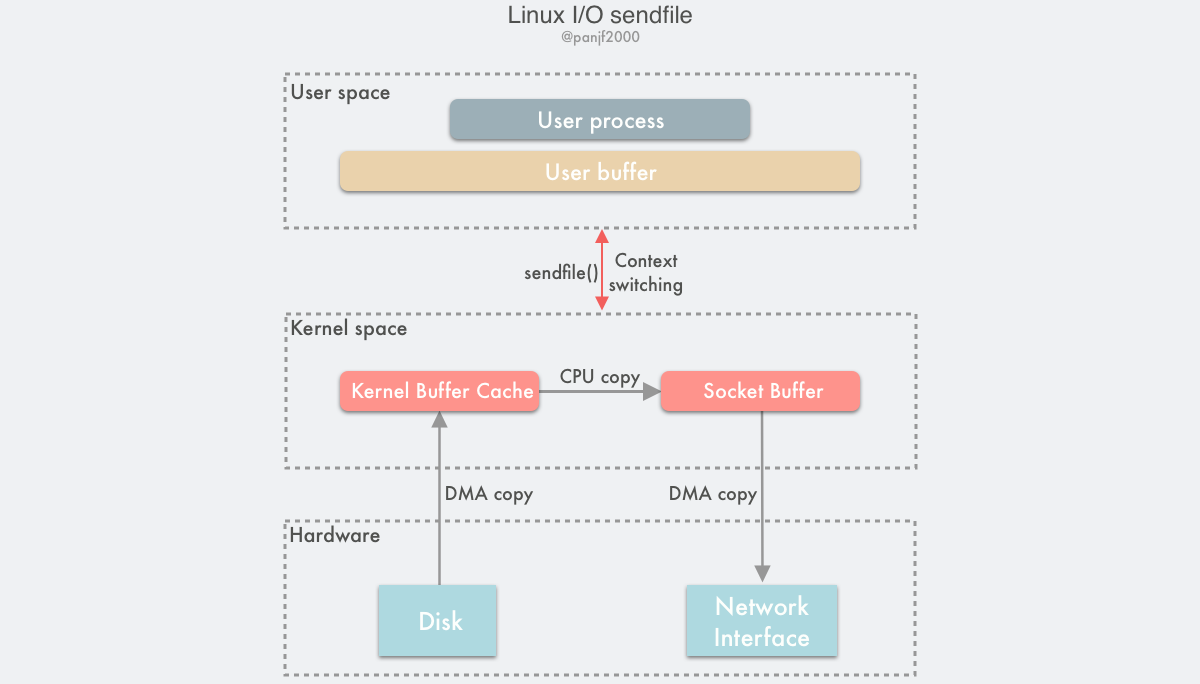
- 用户进程调用
sendfile()从用户态陷入内核态; - DMA 控制器将数据从硬盘拷贝到内核缓冲区;
- CPU 将内核缓冲区中的数据拷贝到套接字缓冲区;
- DMA 控制器将数据从套接字缓冲区拷贝到网卡完成数据传输;
sendfile()返回,上下文从内核态切换回用户态。
基于 sendfile(),整个数据传输过程中共发生 2 次 DMA 拷贝和 1 次 CPU 拷贝,这个和 mmap() + write() 相同,但是因为 sendfile() 只是一次系统调用,因此比前者少了一次用户态和内核态的上下文切换开销。
sendfile() With DMA Scatter/Gather Copy
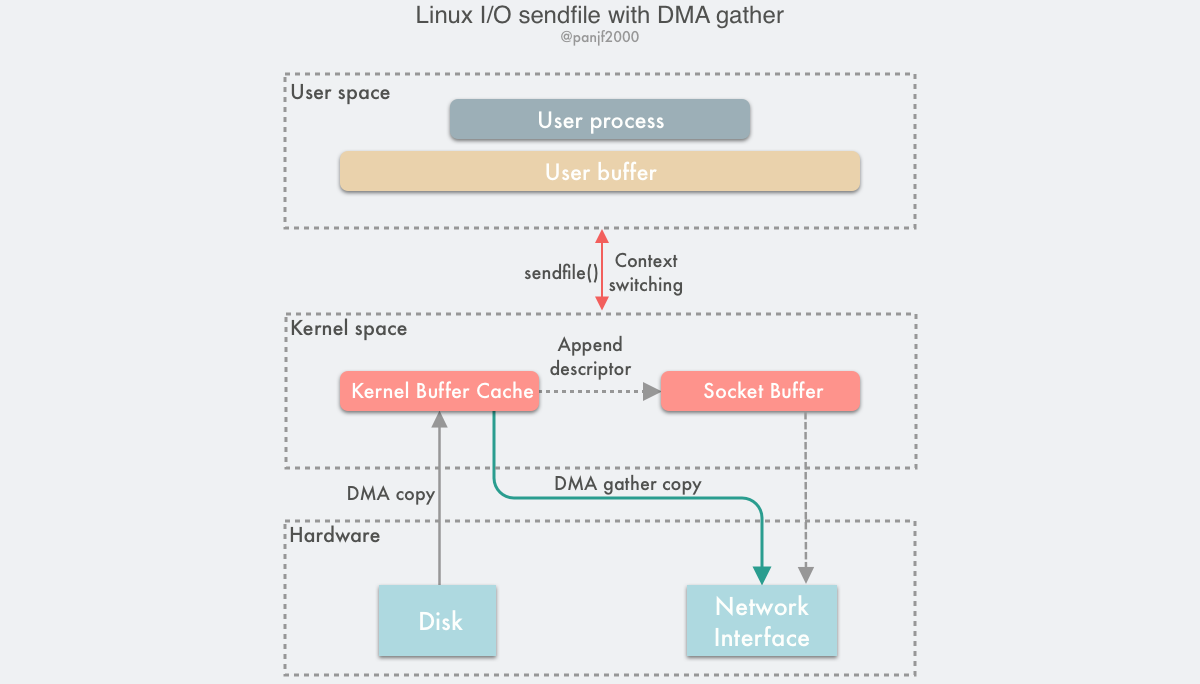
- 用户进程调用
sendfile(),从用户态陷入内核态; - DMA 控制器使用 scatter 功能把数据从硬盘拷贝到内核缓冲区进行离散存储;
- CPU 把包含内存地址和数据长度的缓冲区描述符拷贝到套接字缓冲区,DMA 控制器能够根据这些信息生成网络包数据分组的报头和报尾
- DMA 控制器根据缓冲区描述符里的内存地址和数据大小,使用 scatter-gather 功能开始从内核缓冲区收集离散的数据并组包,最后直接把网络包数据拷贝到网卡完成数据传输;
sendfile()返回,上下文从内核态切换回用户态。
优点:
- 把这仅剩的唯一一次 CPU 拷贝也给去除了 (严格来说还是会有一次,但是因为这次 CPU 拷贝的只是那些微乎其微的元信息,开销几乎可以忽略不计)
缺点:
- 需要新的硬件支持
splice()
splice() 是基于 Linux 的管道缓冲区 (pipe buffer) 机制实现的,所以 splice() 的两个入参文件描述符才要求必须有一个是管道设备
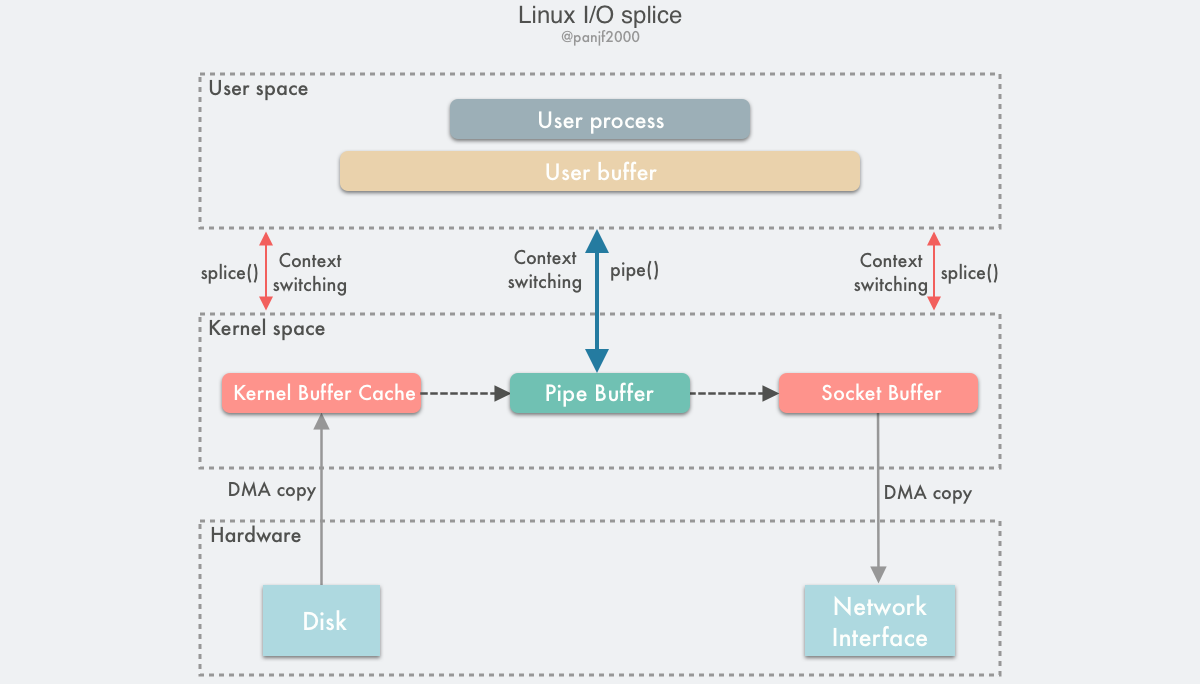
- 用户进程调用
pipe(),从用户态陷入内核态,创建匿名单向管道,pipe()返回,上下文从内核态切换回用户态; - 用户进程调用
splice(),从用户态陷入内核态; - DMA 控制器将数据从硬盘拷贝到内核缓冲区,从管道的写入端"拷贝"进管道,
splice()返回,上下文从内核态回到用户态; - 用户进程再次调用
splice(),从用户态陷入内核态; - 内核把数据从管道的读取端"拷贝"到套接字缓冲区,DMA 控制器将数据从套接字缓冲区拷贝到网卡;
splice()返回,上下文从内核态切换回用户态。
splice() 是基于 pipe buffer 实现的,但是它在通过管道传输数据的时候却是零拷贝,因为它在写入读出时并没有使用 pipe_write() / pipe_read() 真正地在管道缓冲区写入读出数据,而是通过把数据在内存缓冲区中的物理内存页框指针、偏移量和长度赋值给前文提及的 pipe_buffer 中对应的三个字段来完成数据的"拷贝",也就是其实只拷贝了数据的内存地址等元信息。splice() 所谓的写入数据到管道其实并没有真正地拷贝数据,而是玩了个 tricky 的操作:只进行内存地址指针的拷贝而不真正去拷贝数据。
copy_file_range() & FICLONE & FICLONERANGE
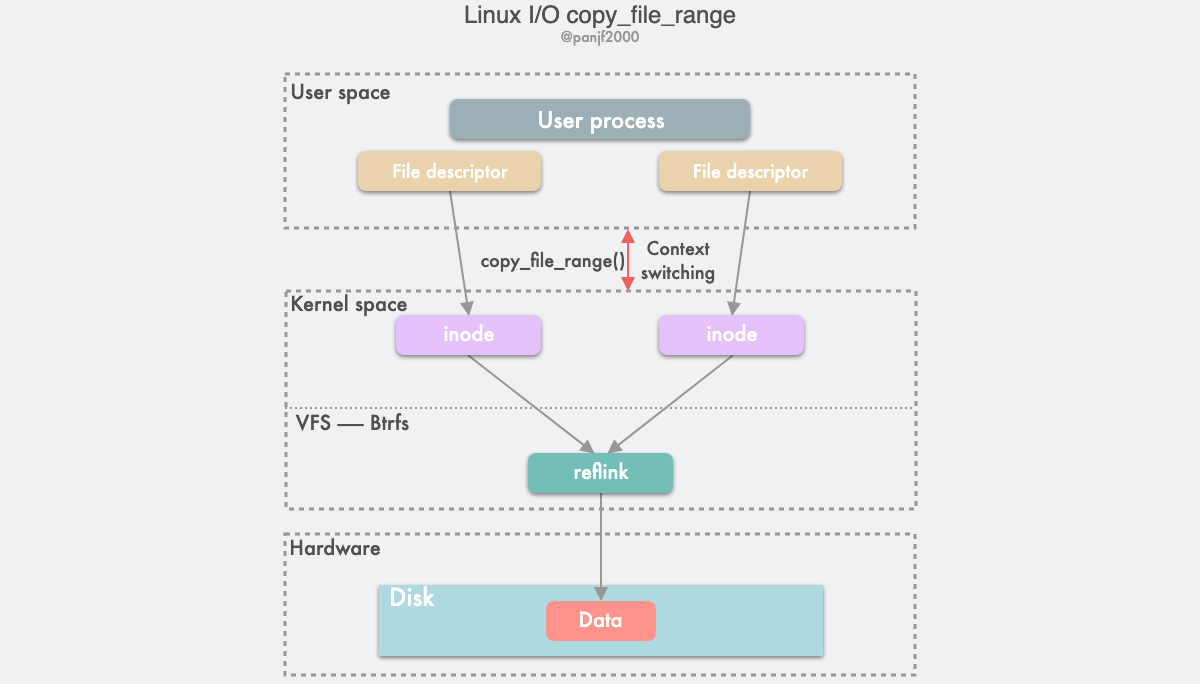
这个系统调用支持拷贝文件的某个范围,可以指定要拷贝到目标文件的源文件的偏移量和长度。前文提及的另一个系统调用 sendfile() 也支持类似的功能。与 sendfile() 一样,copy_file_range() 也是一种内核内 (in-kernel) 的复制,数据拷贝的过程中也同样不需要跨越内核态和用户态的边界,因此也是一种零拷贝技术。
send() With MSG_ZEROCOPY
绕过内核的直接 I/O
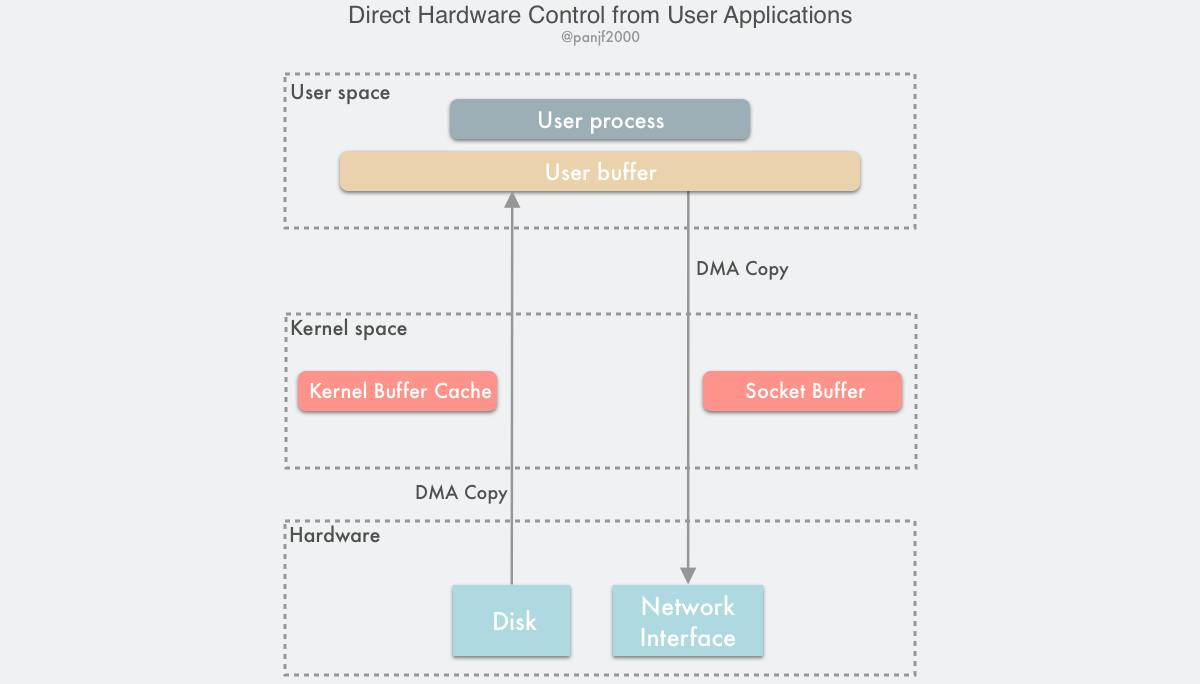
这种方案有两种实现方式:
- 用户直接访问硬件
- 不安全
- 用户空间的数据缓冲区内存页必须进行 page pinning (页锁定)
- 内核控制访问硬件
内核态和用户态之间的传输优化
- 动态重映射与写时拷贝 (Copy-on-Write)
mmap用户进程对于共享缓冲区进行同步阻塞读写才能避免 data race 的问题,COW 可以实现异步对共享缓冲区进行读写- CoW 这种零拷贝技术比较适用于那种多读少写从而使得 CoW 事件发生较少的场景,因为 CoW 事件所带来的系统开销要远远高于一次 CPU 拷贝所产生的
- 缓冲区共享 (Buffer Sharing)
为了实现这种传统的 I/O 模式,Linux 必须要在每一个 I/O 操作时都进行内存虚拟映射和解除。这种内存页重映射的机制的效率严重受限于缓存体系结构、MMU 地址转换速度和 TLB 命中率。如果能够避免处理 I/O 请求的虚拟地址转换和 TLB 刷新所带来的开销,则有可能极大地提升 I/O 性能。而缓冲区共享就是用来解决上述问题的一种技术。
统的 Linux I/O 接口是通过把数据在用户缓冲区和内核缓冲区之间进行拷贝传输来完成的,这种数据传输过程中需要进行大量的数据拷贝,同时由于虚拟内存技术的存在,I/O 过程中还需要频繁地通过 MMU 进行虚拟内存地址到物理内存地址的转换,高速缓存的汰换以及 TLB 的刷新,这些操作均会导致性能的损耗。而如果利用fbufs框架来实现数据传输的话,首先可以把 buffers 都缓存到 pool 里循环利用,而不需要每次都去重新分配,而且缓存下来的不止有 buffers 本身,而且还会把虚拟内存地址到物理内存地址的映射关系也缓存下来,也就可以避免每次都进行地址转换,从发送接收数据的层面来说,用户进程和 I/O 子系统比如设备驱动程序、网卡等可以直接传输整个缓冲区本身而不是其中的数据内容,也可以理解成是传输内存地址指针,这样就就避免了大量的数据内容拷贝:用户进程/ IO 子系统通过发送一个个的fbuf写出数据到内核而非直接传递数据内容,相对应的,用户进程/ IO 子系统通过接收一个个的fbuf而从内核读入数据,这样就能减少传统的read()/write()系统调用带来的数据拷贝开销:
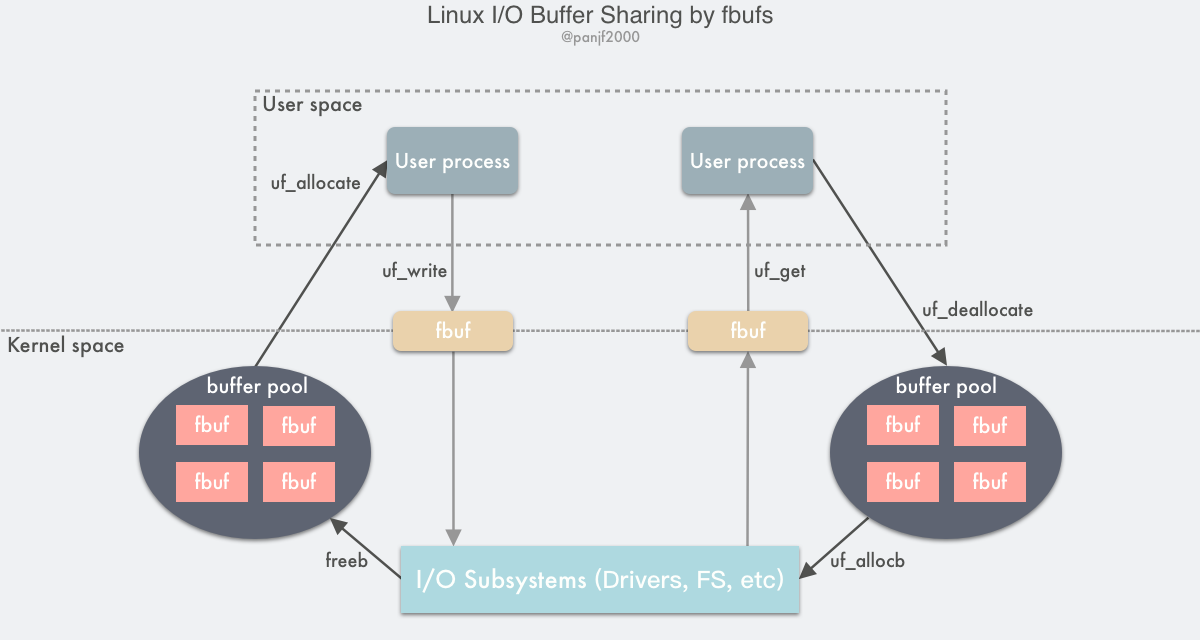
- 发送方用户进程调用
uf_allocate从自己的 buffer pool 获取一个fbuf缓冲区,往其中填充内容之后调用uf_write向内核区发送指向fbuf的文件描述符; - I/O 子系统接收到
fbuf之后,调用uf_allocb从接收方用户进程的 buffer pool 获取一个fubf并用接收到的数据进行填充,然后向用户区发送指向fbuf的文件描述符; - 接收方用户进程调用
uf_get接收到 fbuf,读取数据进行处理,完成之后调用uf_deallocate把fbuf放回自己的 buffer pool。