HDD
I/O 程序的优化工作基本是围绕着降低 I/O 操作的磁盘寻址时间从而提升 I/O 系统的全局吞吐量来做的,因为对于 HDD 磁盘来说,磁盘 I/O 的性能瓶颈主要集中在磁盘的寻址操作上,核心的优化策略就是合并与排序。
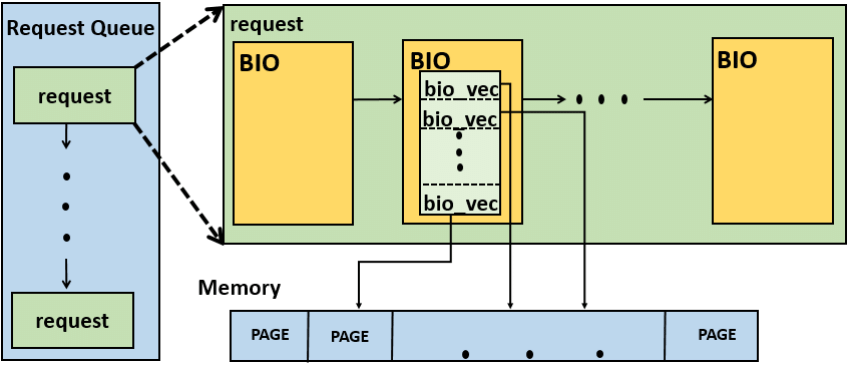
在 HDD 磁盘占主流的年代,I/O 操作的性能瓶颈主要集中在磁盘本身,也就是磁盘寻址和磁盘读写,通常 HDD 的随机 I/O 只能达到几百 IOPS (input/output operations per second),所以单队列调度架构(SQ) 对于 HDD 硬盘的性能需求来说已经足够了。
单队列 I/O 调度程序 (Single-queue I/O schedulers)
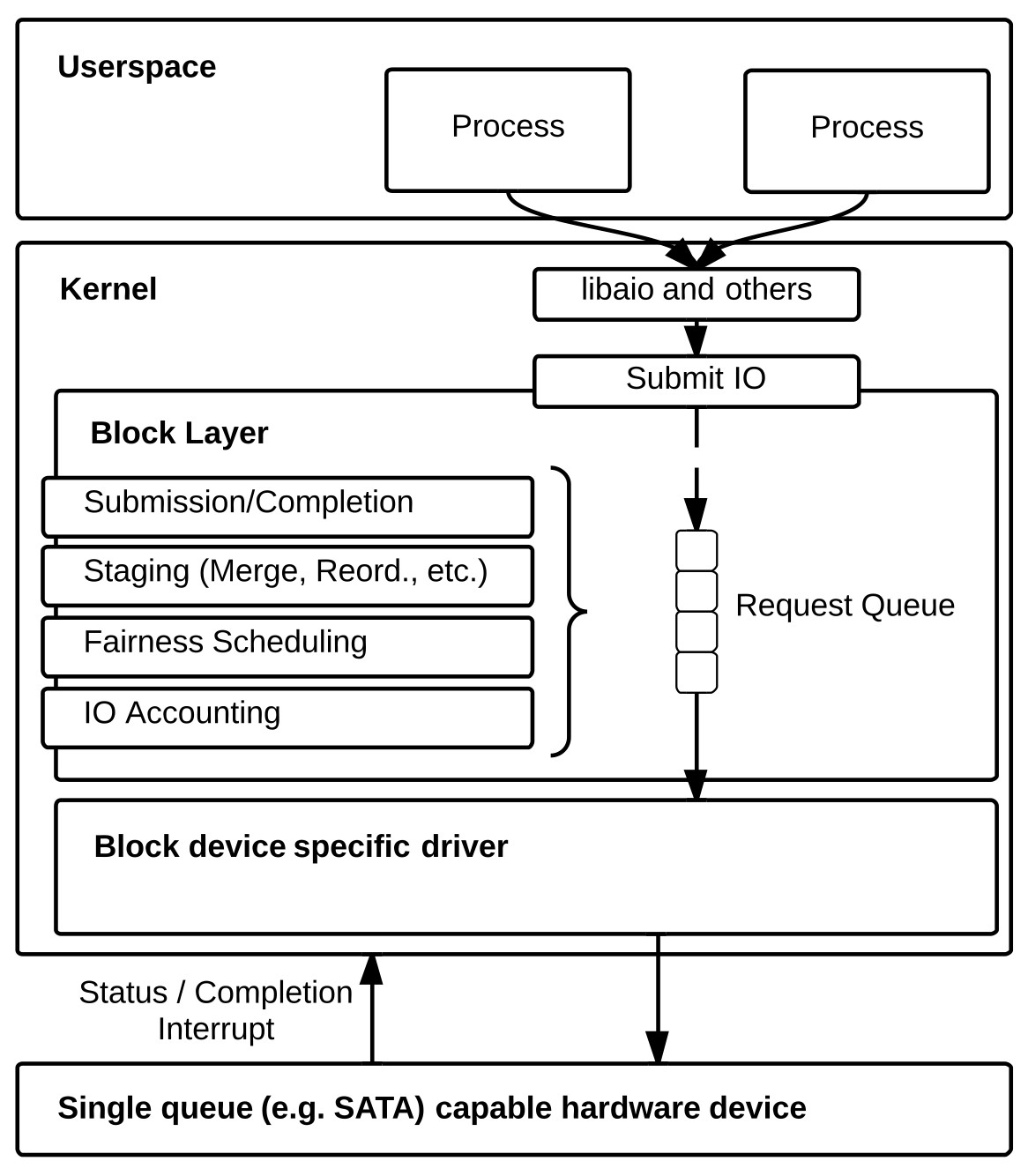
Linus 电梯算法
Linus 电梯算法是第一个 I/O 调度算法,在 2.4 版内核中首次引入。其原理遵循我们前面介绍的合并与排序优化:检测到新 I/O 请求进入队列的时候,它就会逐一检查当前队列中的每一个待处理的 I/O 请求是否可以与新请求合并,如果可以就合并请求;否则的话,它就会尝试按照磁盘扇区地址的顺序为这个新请求在队列中寻找合适插入点 (排序优化),如果找到便直接插入,要是没找到合适的位置,就将其插入到队尾。
Deadline 算法
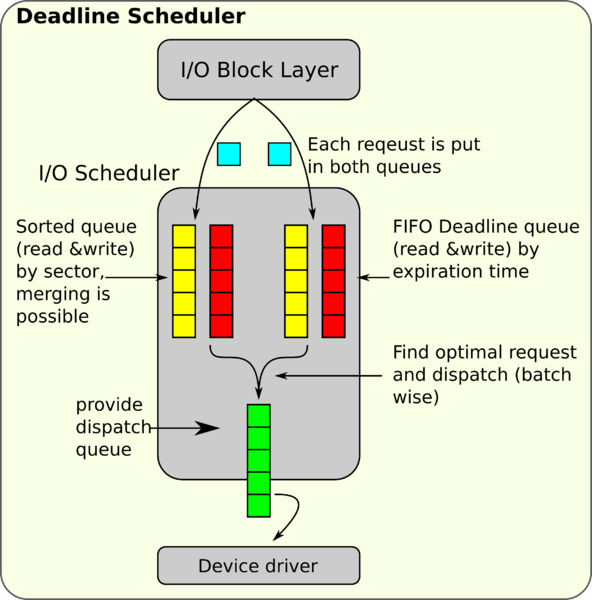
Deadline 算法是为了解决 Linus 电梯算法所带来的饥饿问题而引入的。它的工作原理基本和 Linus 电梯算法是一样的,但是它为每一个 I/O 请求加上了过期时间,这个算法中有两种队列:Sorted Queue —— 将 I/O 请求按磁盘地址排序并尝试合并,FIFO Queue —— 将 I/O 请求按过期时间排序。默认情况下,读请求是 500ms,写请求是 5s。这个算法对多读少写的场景更加友好,因此该算法比较适合 I/O 密集的应用,比如数据库。
CFQ (Completely Fair Queueing) 算法
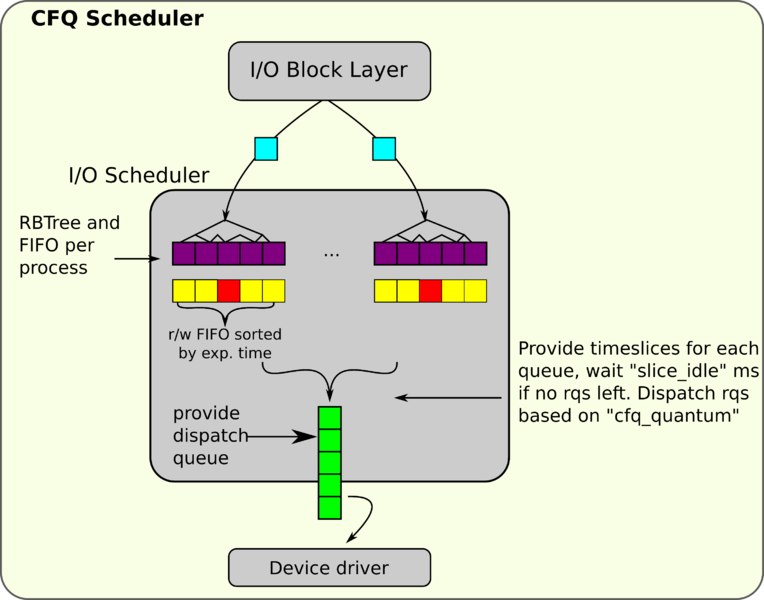
CFQ 算法的主要目标是尽量公平地把磁盘 I/O 带宽分配给所有的用户进程。CFQ 也有Sorted Queue和FIFO Queue,区别是前者使用红黑树实现。CFQ 算法以时间片轮询调度队列,每一轮都从每个队列中取出一定数量 (默认是 4,可更改) 的 I/O 请求数进行调度以实现公平。
这个算法是专门为多媒体设备 (音视频) 和个人电脑而设计的,比如说个人电脑,用户通常会同时开启多个任务一起执行,比如写文档的时候听音乐,同时还在下载东西,这个时候要公平地协调系统的 I/O 资源,保证用户能同时执行这些任务而不会卡顿,虽说这个算法很适合多任务系统,但是因为 CFQ 算法的通用性,所以它在其他场景也能运行得很好。
Noop (No-operation) 算法
I/O 调度程序实现的最简单的调度算法,其核心逻辑是只应用合并优化而放弃排序优化。这个算法是专门为随机访问设备而设计的,比如 Flash 闪存盘,RAM 盘等,也非常适合那些能够提前把 I/O 请求排好序的高级存储控制器。
SSD
随着 SSD 硬盘逐渐取代 HDD 硬盘成为主流,磁盘的 IOPS 也如同坐火箭般高速飞升,随机 I/O 的 IOPS 从原来的几百到现在的十万级甚至未来的百万级。于是局面反转了,原先的性能瓶颈在磁盘,现如今转移到了 Linux 内核的 SQ I/O 调度程序上,再加上以 NUMA (Non-Uniform Memory Access) 多核架构和 NVMe (Non-Volatile Memory express) 通信协议的横空出世,计算机系统的多核处理与数据传输能力也与日俱增,更是进一步加剧了内核的 SQ I/O 调度架构的性能滞后。因此内核亟需引入新的 I/O 调度架构来跟上 SSD 的速度,将 SSD 的速度潜能都发挥出来。
SQ I/O 调度程序在扩展性方面的三个主要的问题:
- 请求队列锁:SQ 在并发处理的场景下带来的是粗粒度的锁机制和激烈的锁竞争
- 硬件中断:高 IOPS 伴随着高频次的硬件中断,当下大部分存储设备都被设计成由一个 CPU 全权负责处理所有的硬中断,不论 I/O 请求是不是它自己发出的,它都会通过软中断的方式转发给其他 CPU。因此仅一次 I/O 就要触发两次硬件中断
- 远端内存访问:共享的队列数据(锁状态等)会使得 NUMA 架构下的 CPU 之间的缓存失效(MESI 协议)
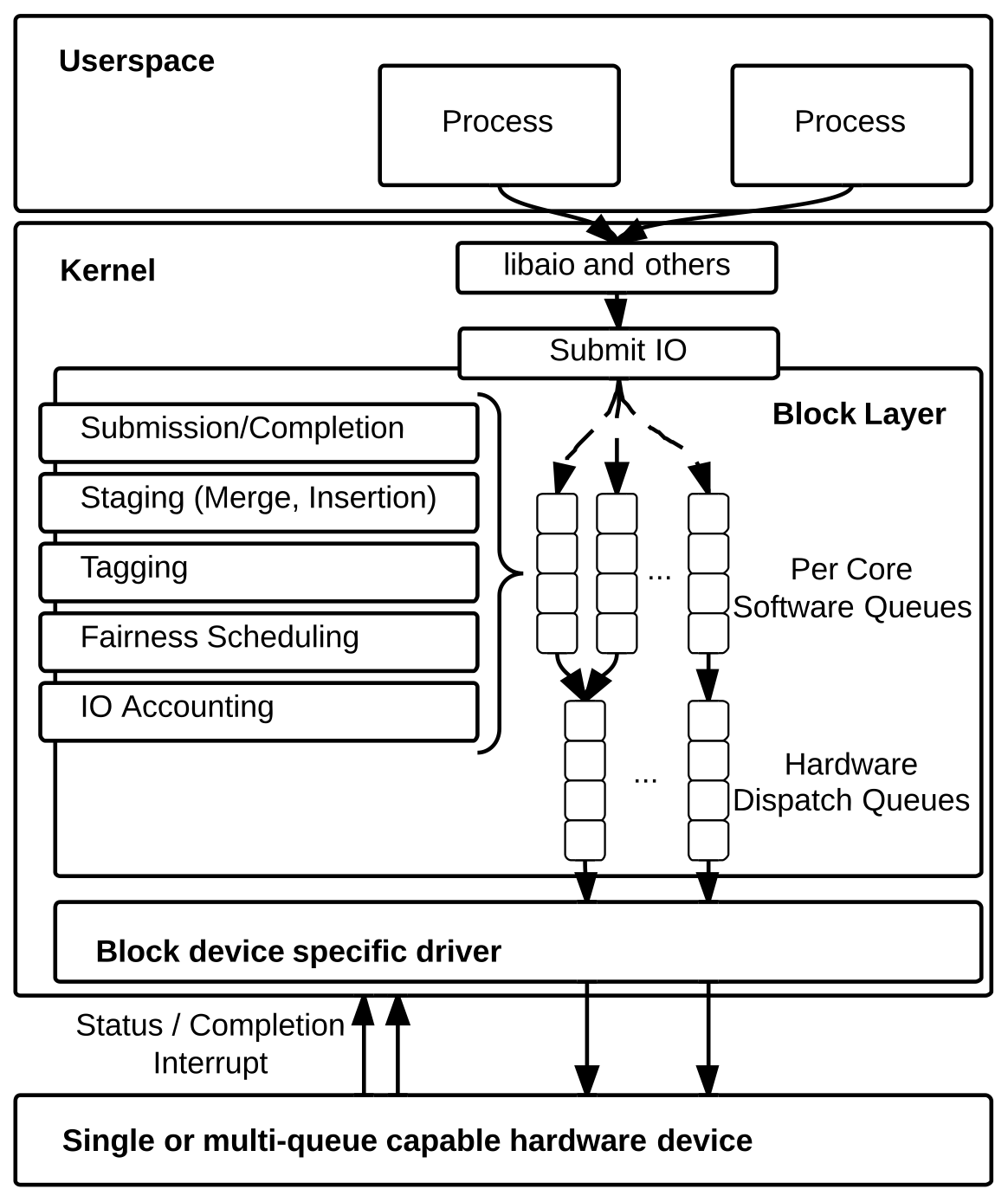
SSD 的软件层工作原理:
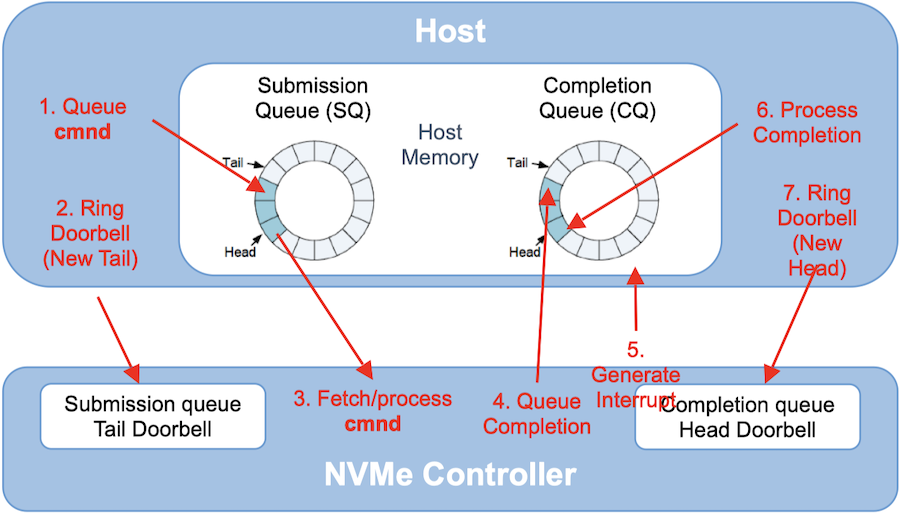
主机往其内存 (或者硬盘的内存) 中的 I/O Submission 环形队列写进一个 I/O 命令 (command, 主机驱动硬盘工作的原理就是通过一个个的 I/O command),同时往一个叫 doorbell 的寄存器里写入一个 I/O 命令就绪的信号,然后 NVMe SSD 的控制器按照命令的接收顺序或优先级顺序从队列中取出 I/O 命令并执行,完成之后便往 I/O Completion 队列写入命令已完成的状态,随后向主机发出一个中断信号。主机收到之后会记录下 I/O Completion 队列中的命令已完成状态,最后清除掉 doorbell 寄存器里的内容。
Multi-Queue Block IO Queueing Mechanism (blk-mq)
MQ-Deadline Scheduler
MQ-Deadline 是内核从 SQ 往 MQ 架构转变的过程中的第一个 MQ 实现,这个 mq-deadline scheduler 是直接从 SQ 中的 deadline scheduler 重构而来的一个改版,专门针对多队列设备而改造,其特定是通用性很好、实现简单、调度过程中 CPU 开销很低。
BFQ (Budget Fair Queueing) Scheduler
BFQ 调度器在 4.12 内核中首次实现 41,是一种"比例配额" (proportional-share) 的低延迟 I/O 调度器,支持 cgroups。BFQ 的架构是从 CFQ 借鉴过来的,同时也借鉴了大量的代码。其公平性调度是主要是基于 I/O 请求的扇区数。BFQ 比较适合多媒体设备,比如个人电脑,或者是一些为实时应用服务的后端服务器,比如视频直播、游戏等。
Kyber I/O Scheduler
None
基本原理和 SQ 架构下的 noop 算法一致:用来缓冲 I/O 请求的队列是 FIFO,而且不执行排序优化,只做合并优化。None 基本上就是把 noop 进行多队列的改造,为每一个 CPU core 或者 NUMA node 配备一个本地 FIFO 队列,避免跨核内存访问和锁竞争。