Flows
背景
CDN 场景下两种 MRC:
- OMRC:与访问延时更相关
- BMRC:更加精确的刻画了带宽压力和服务提供商的成本
在异构尺寸的 CDN 场景下无法精确估计 MRC 的原因有:
- 对于请求的采样不均衡
- 对象的异构热度和异构尺寸
现有的方法:
- SHARDS:用哈希做采样,降低复杂度,但是会导致一个大尺寸的对象漏采(影响 BMRC)或者一个高热度的对象漏采(影响 OMRC)
- HPCC:在 SHARDS 上做改进,在头部增加一个小尺寸的 Cache,认为漏采的都会被这个小尺寸的采上,但是 BMRC 上的性能仍然不好
创新点
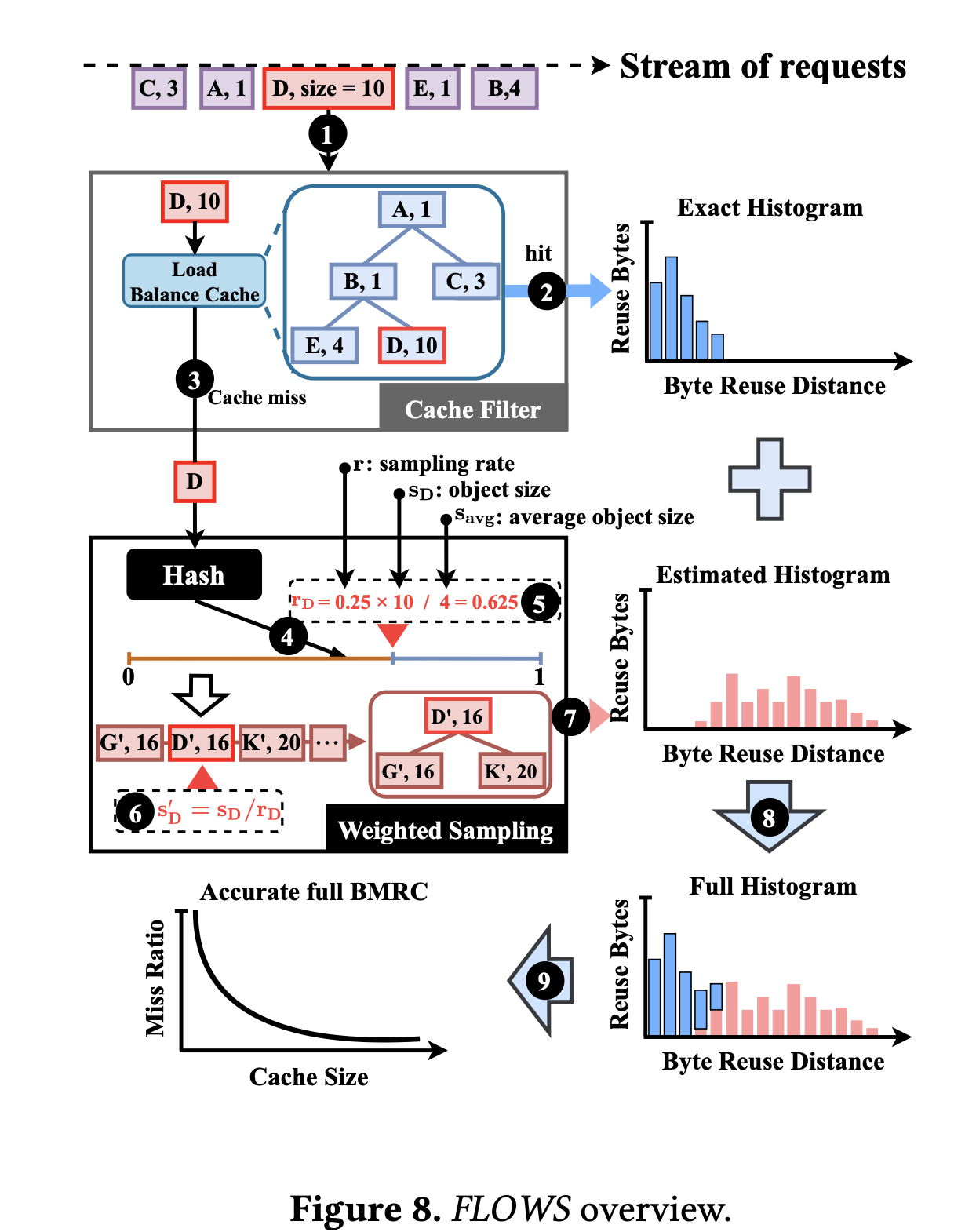
Cache Filter
一个小的固定长度的 LRU cache 以及一个搜索树(splay tree)来计算重用距离,这个小 Cache 实际上相当于一个负载均衡器,可以滤掉一部分热度高的负载,让后端的负载更加均衡
Weighted Sampling
对每个尺寸大小的目标采用不同的采样率
Cache Allocation
优化目标
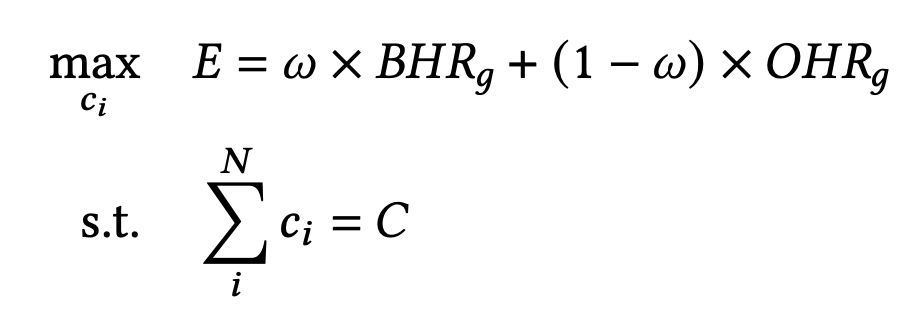
系统设计
Buffer More, Flush Less
背景
- 由于小写的存在,EC 的读改写会有远高于副本存储的流量放大
- 使用缓存是降低流量放大最简单的思路。在 EC 层上构建一个副本缓存,将小写聚合为大块,异步将大块写下刷到 EC 存储层,进而减低降低系统整体的流量开销。对于大块写,直接写入 EC 存储层。
- 由于纠删码读改写的存在,下刷数据存在二次流量放大。因此相比提供更高的写命中率,更低的下刷流量才是关键。
- 小写热点数量多
- 大写在热点中流量占主导
方法
首先根据当前的集群基础流量调度各个节点在不同存储类型上流量的比例,避免节点的过载;其次在节点内部实现精细的冷热流量分离器,降低由于缓存下刷导致的流量放大。
- 基于拓扑(负载)的节点压力建模——线性规划求解每个节点应该如何在不同冗余之间选择
- 高效块热度统计和查询——决策如何获得规定比例的高热度流量进入缓存
假设计算出需要将 30%的流量进行 EC 直写 (EC 实现:jerasure/intel 开源),那么如何获得 30%的流量呢。首先这些流量一定都尽量来自于大 IO,但是直方图统计有一定的延迟性,并且如果让低热度块进到了 Cache 层,则有可能导致 Cache 层频繁下刷,导致流量增加

对于高频的大块,我们应该写到 cache 层,减少 cache 的下刷。对于大块的冷数据,应该写入 EC 层,避免缓存污染。
整体的流量放大来自 3 个部分,分别是副本复制、EC 直写和副本下刷。我们已经限制直写和副本复制的流量比例,并且 EC 直写的流量都是大块流量,因此我们可以认为副本复制和 EC 直写的放大不变。因此主要需要解决的是副本下刷的流量,就是最小化副本下刷的数据量。
相同 IO size:热度越高,则越值得缓存。减少下刷的量。
相同热度:size 越小,越值得缓存。减少直写的放大。
Count-Min Scatch
