FILE TAG
Distributed
START
Basic
什么是CAP 理论
Back:
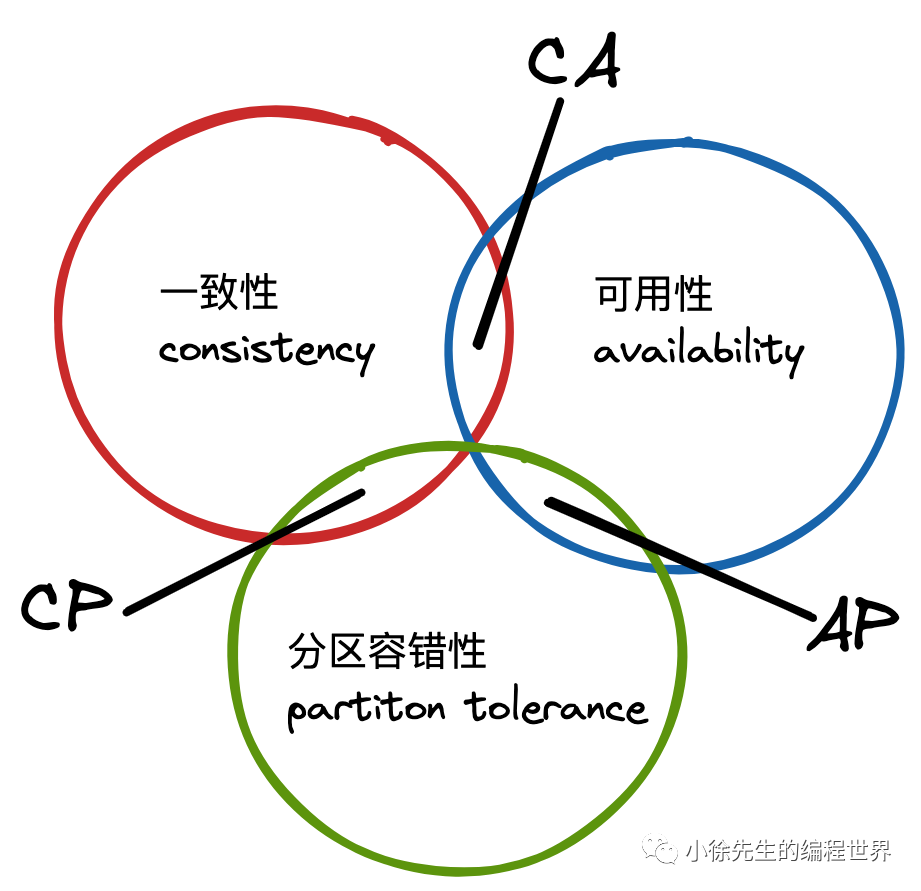
对于分布式系统而言, P 是必须得到保证的,否则这就违背了“分布式”的语义. 那么分布式系统会分为两种流派:
(1)CP:强调系统数据的正确性,但由于建立保证不同节点间保证数据严格一致的机制,可能会牺牲系统的可用性.
(2)AP:强调系统的可用性,那就必须在数据一致性上做出妥协退让.
C 的问题
(1)即时一致性问题(异步同步会读到老数据)
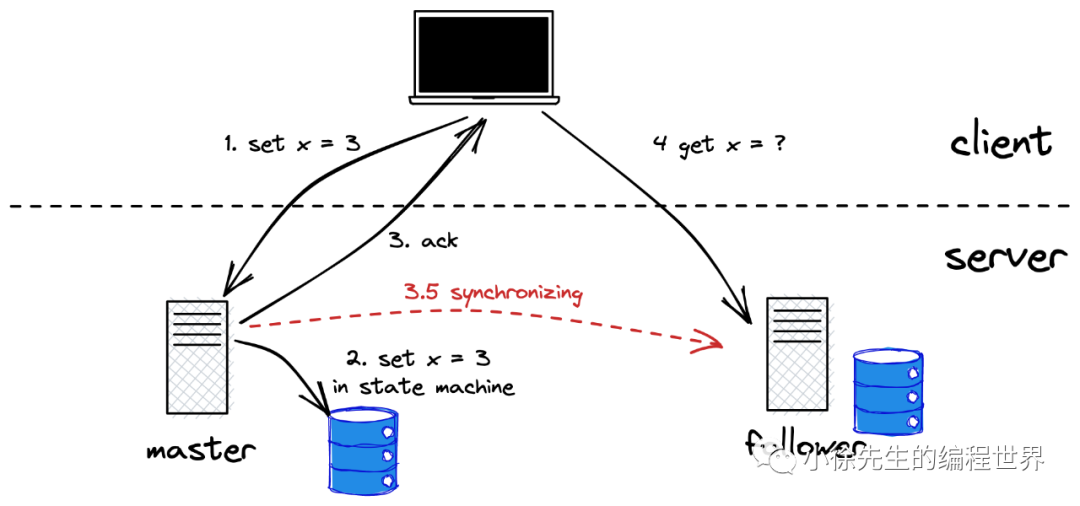
(2)顺序一致性问题(请求的顺序发生了问题,导致最终一致性都没办法保证)
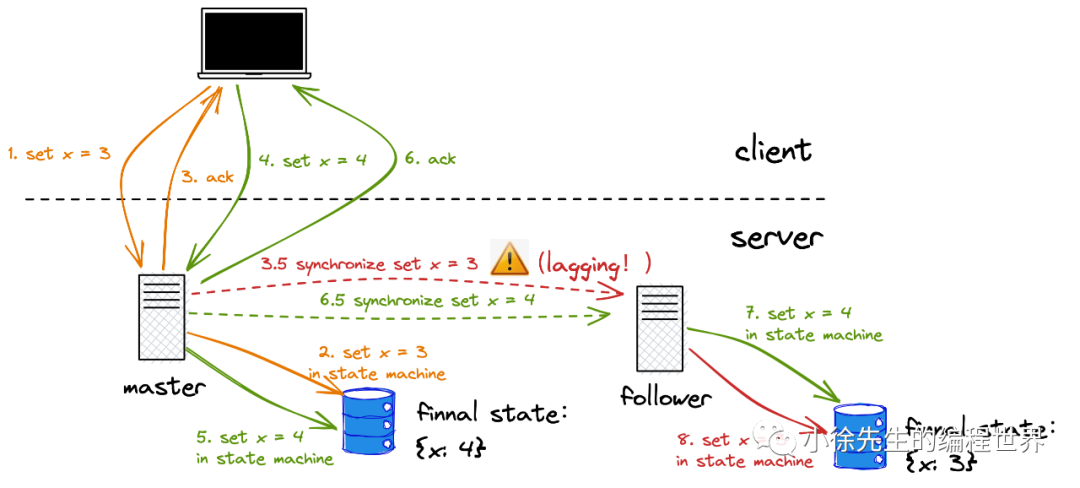
A 的问题
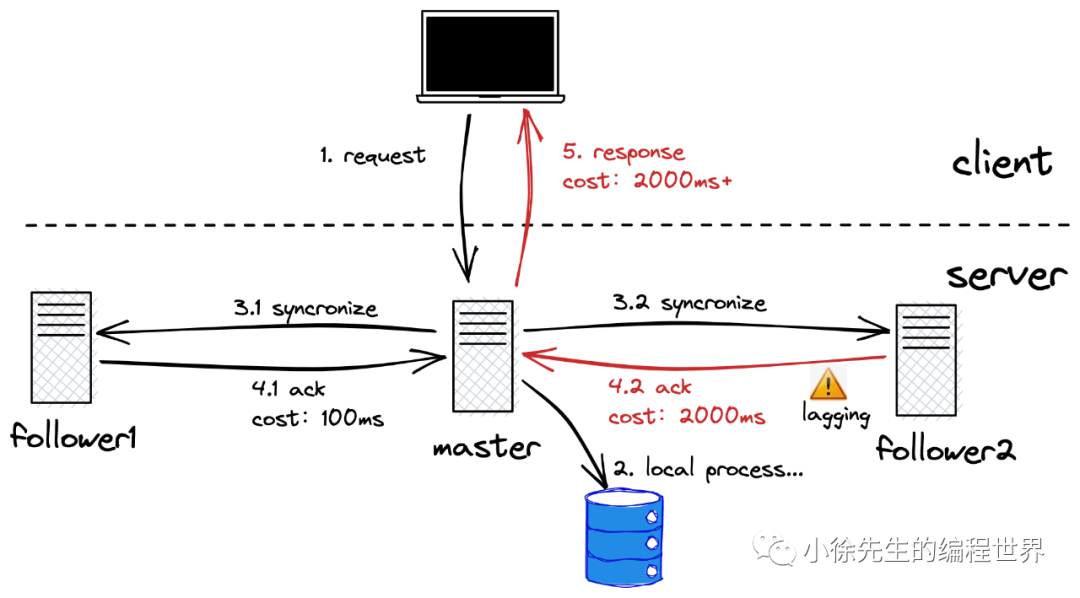
全部串行化,会导致木桶效应,使得集群的可用性受到影响
END
START
Basic
Raft 一致性算法有哪些核心
Back:
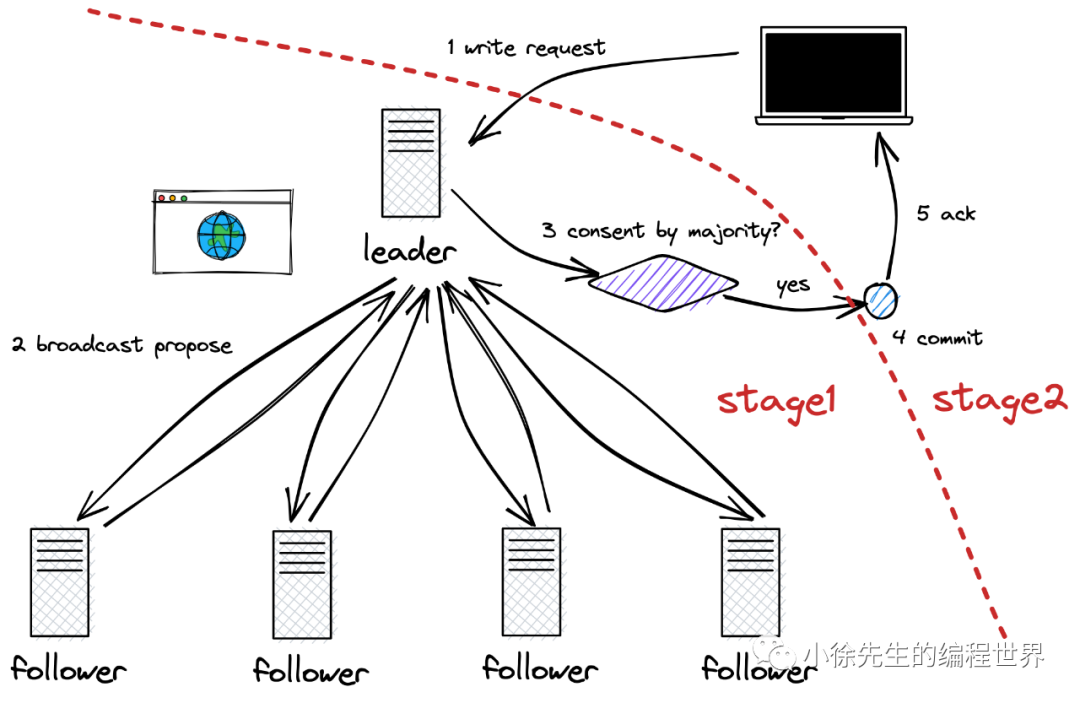
协议约定:
- 多数派原则
- 一主多从
- 读写分离
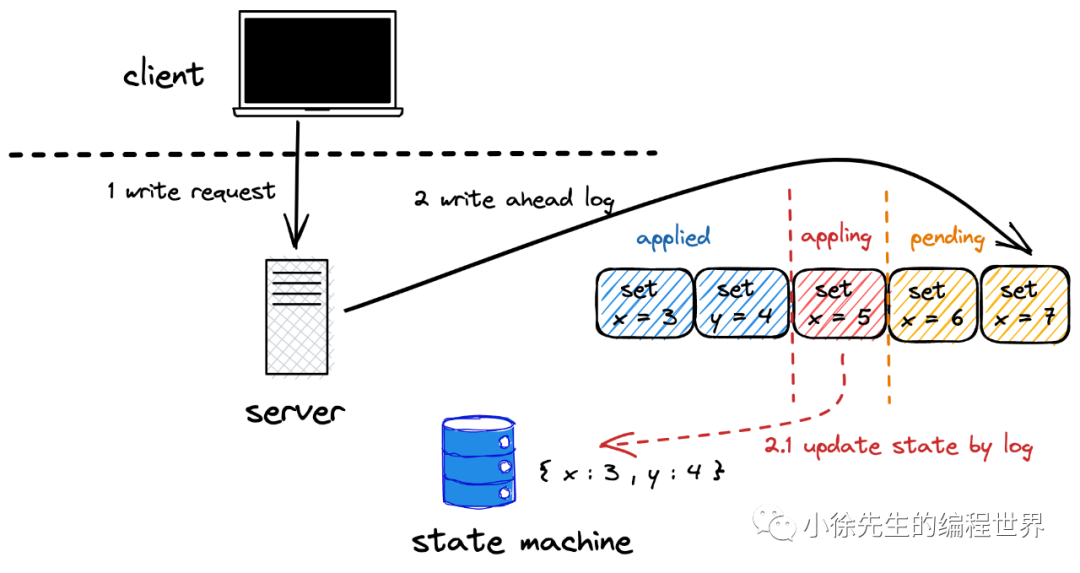
状态机与预写日志(WAL)
预写日志:记录写请求明细的日志(单指 Raft 下狭义的日志)
状态机:节点内存储数据的介质
两阶段提交
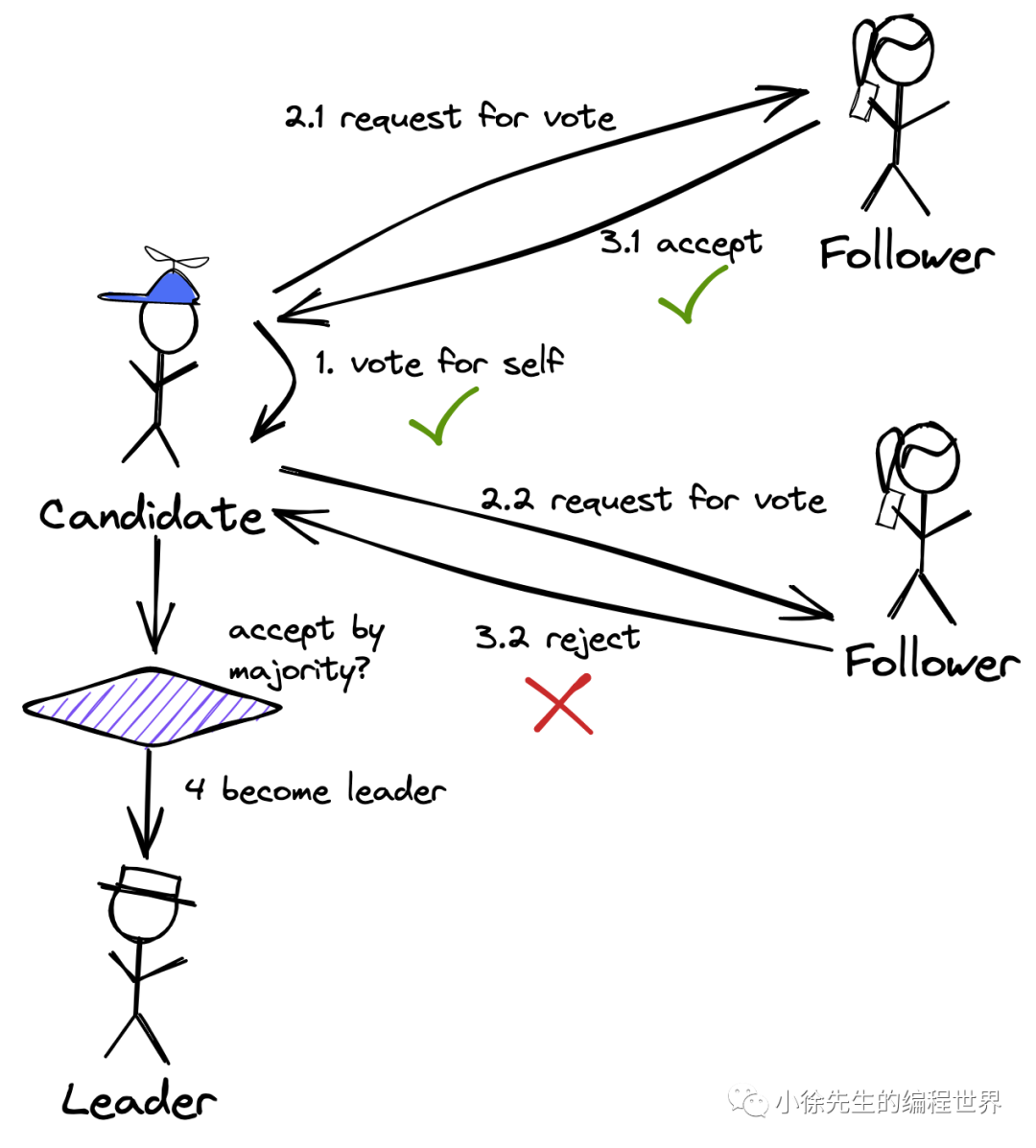
角色定义和切换
领导者
跟随者
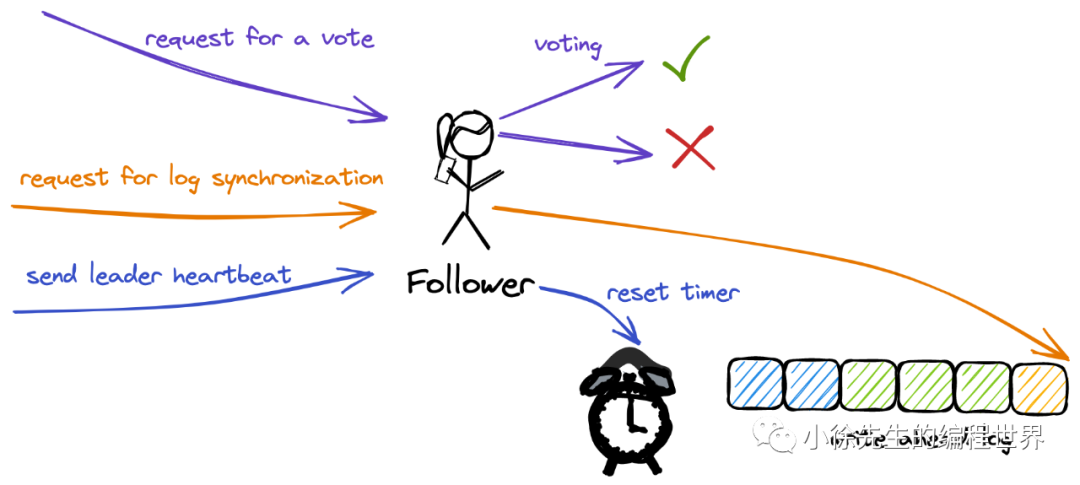
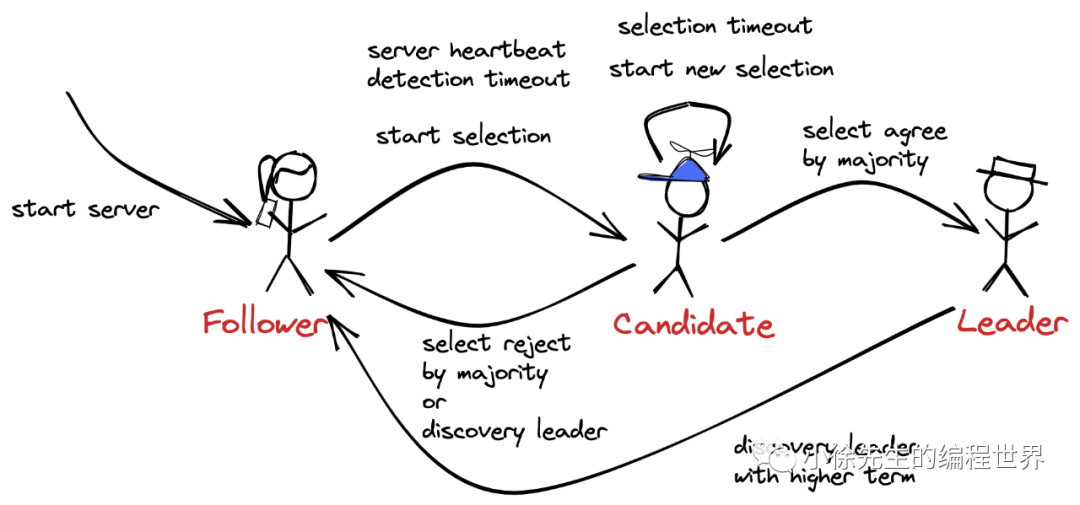
这里的 timer 通常采用随机初始化的方式,防止某些情况产生
候选人
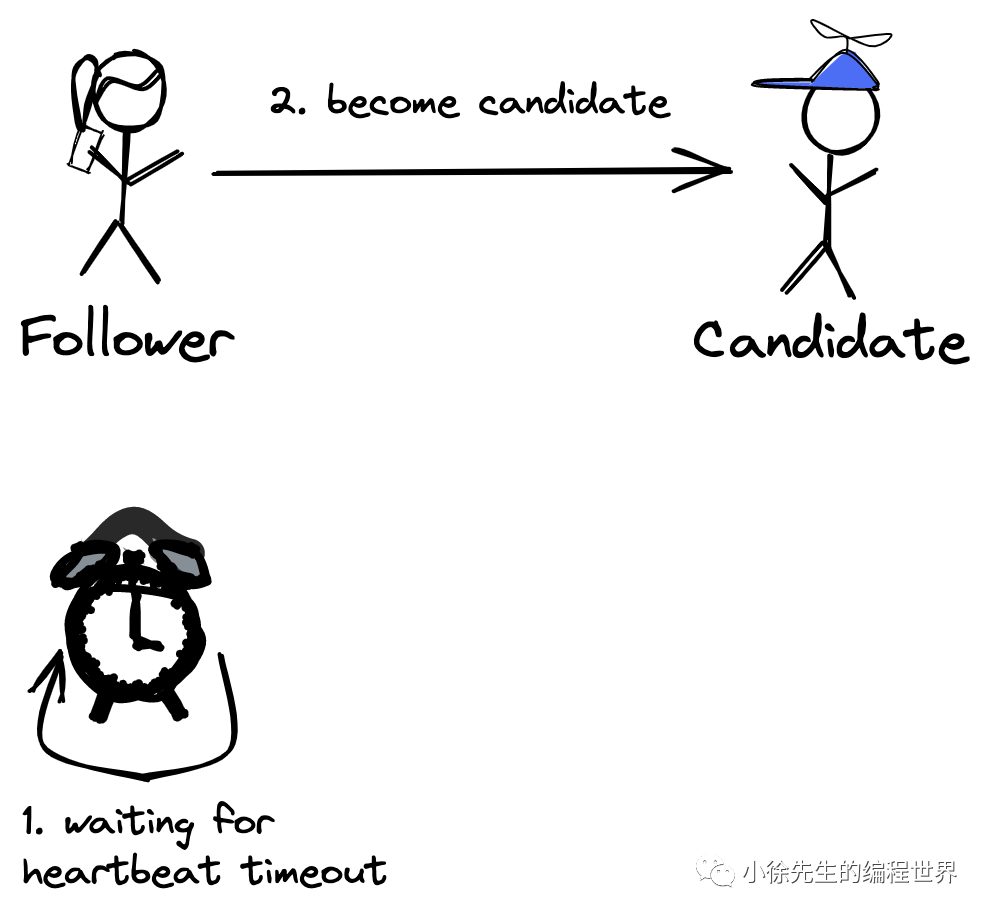
极端情况下,有可能在集群中存在且仅存在两个 Candidate,如果以同样的 timeout 开始选举流程,他们都会将自己的票投给自己,从而永远也获得不了多数派的选票,从而一直发生竞争选举,因此这里的 timeout 通常会随机初始化一个值,以错开选举流程
END
START
Basic
Raft 算法下的外部请求流程
Back:
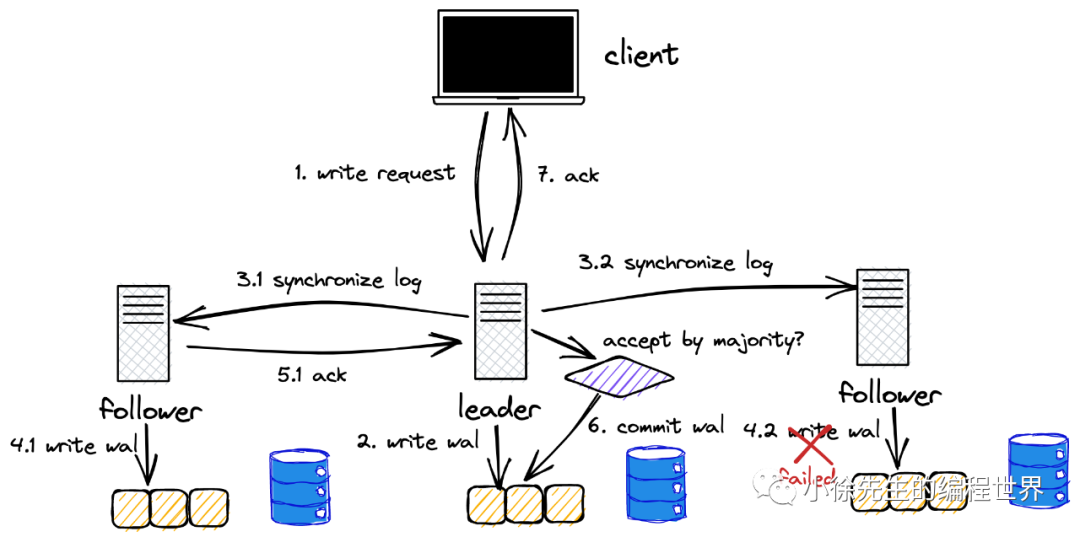
写请求
-
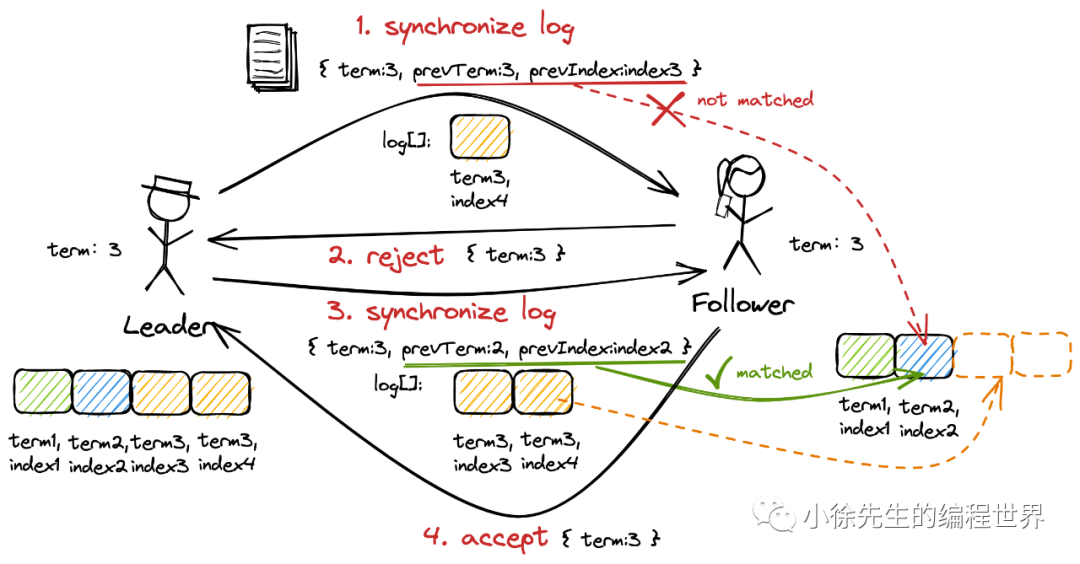
若 follower 日志滞后
follower 会拒绝 leader 的同步请求;leader 发现 follower 响应的任期与自身相同却又拒绝同步,会递归尝试向 follower 同步预写日志数组中的前一笔日志,直到补齐 follower 缺失的全部日志后,流程则会回归到正常的轨道.
-
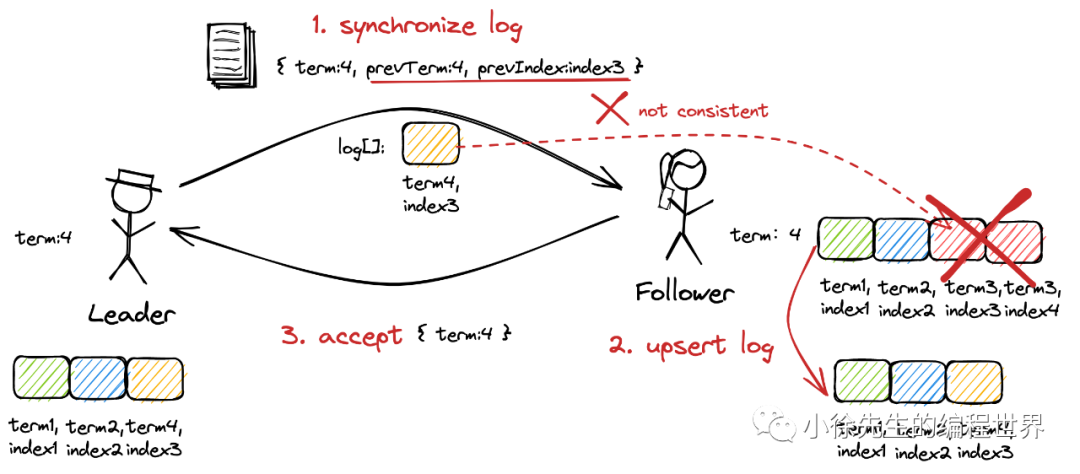
若 follower 日志“超前“
follower 在 leader 最新同步日志的索引及其之后已存在日志,且日志内容还与当前 leader 不一致. 此时 follower 需要移除这部分”超前“的日志,然后同步 leader 传送的日志,向当前在任 leader 看齐
读请求
读请求没什么特别的,所有的节点都可以处理读请求,但是在不提供额外机制的情况下,Raft 只能保证最终一致性
END
START
Basic
Raft 算法下的内部请求流程
Back:
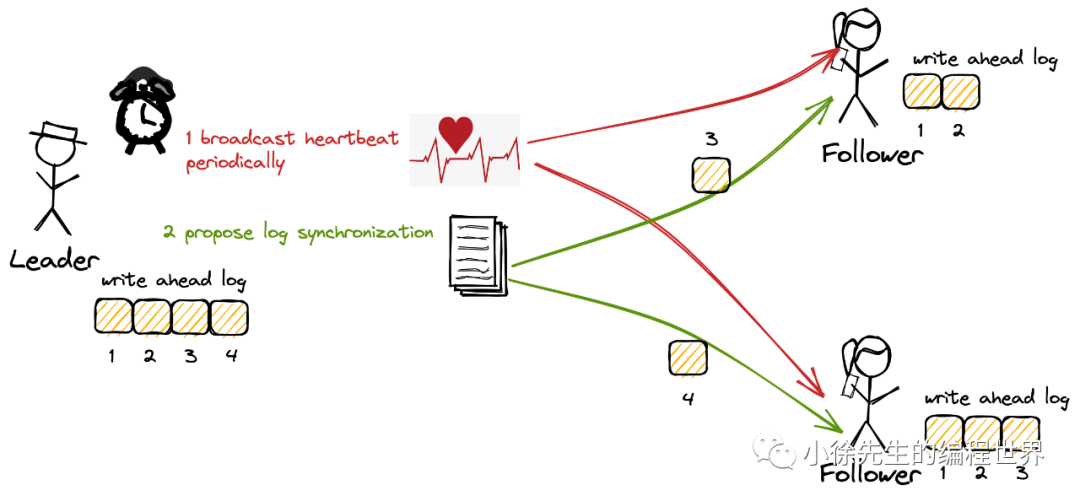
日志同步请求
- leader 向所有节点提proposal
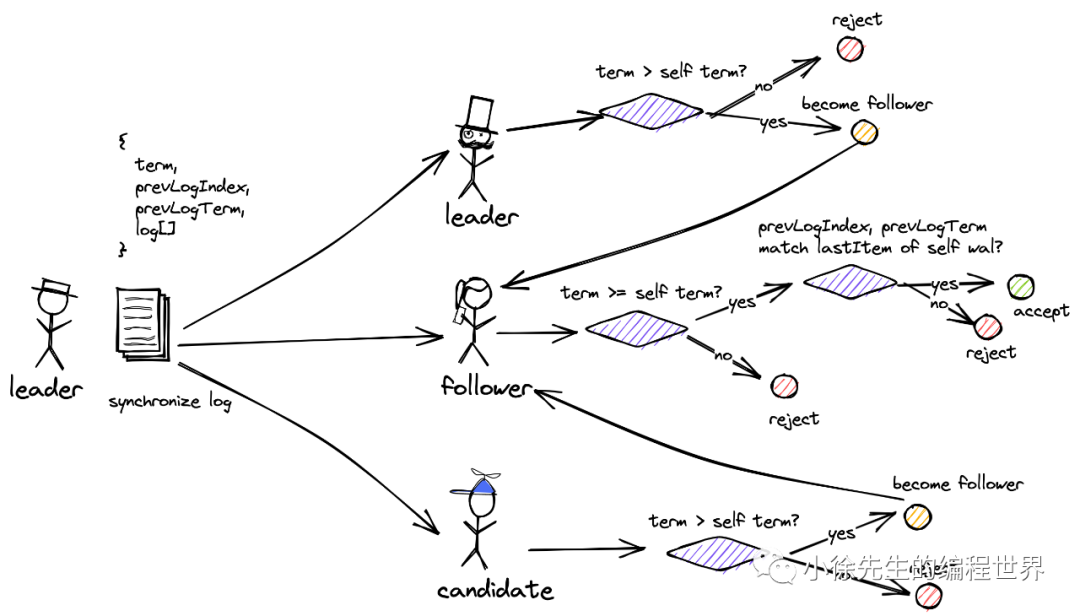
- 节点收到 proposal 后回复 leader
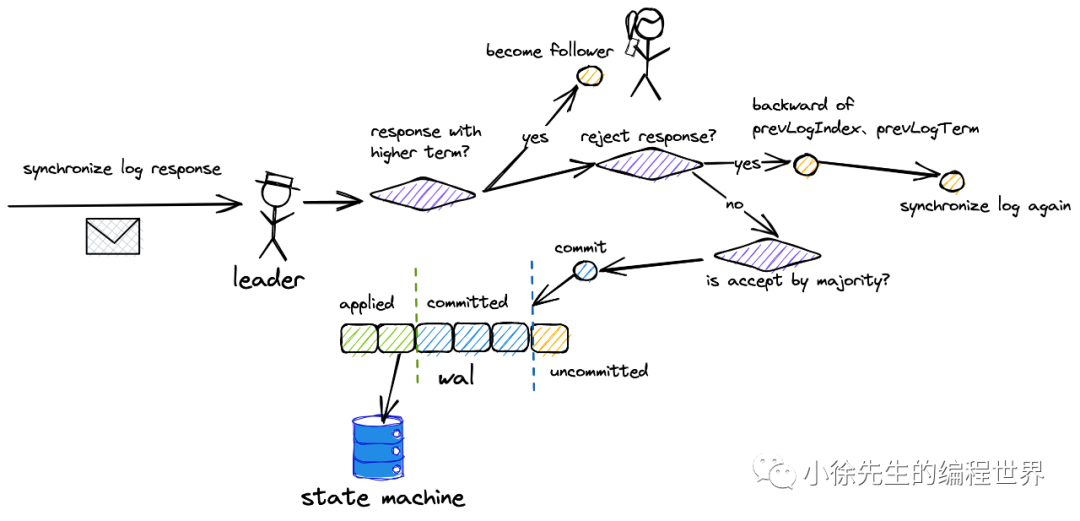
心跳&提交同步请求
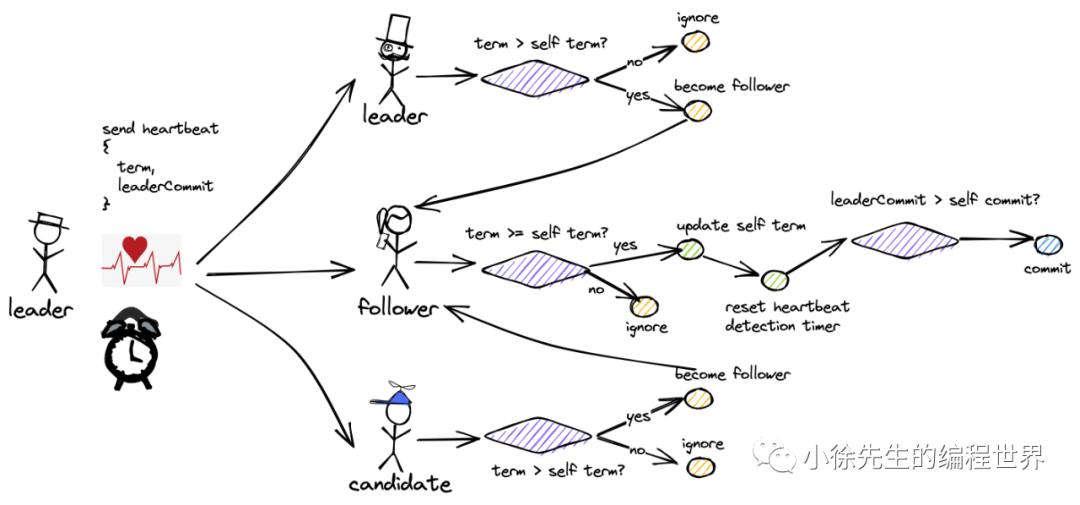
竞选拉票请求
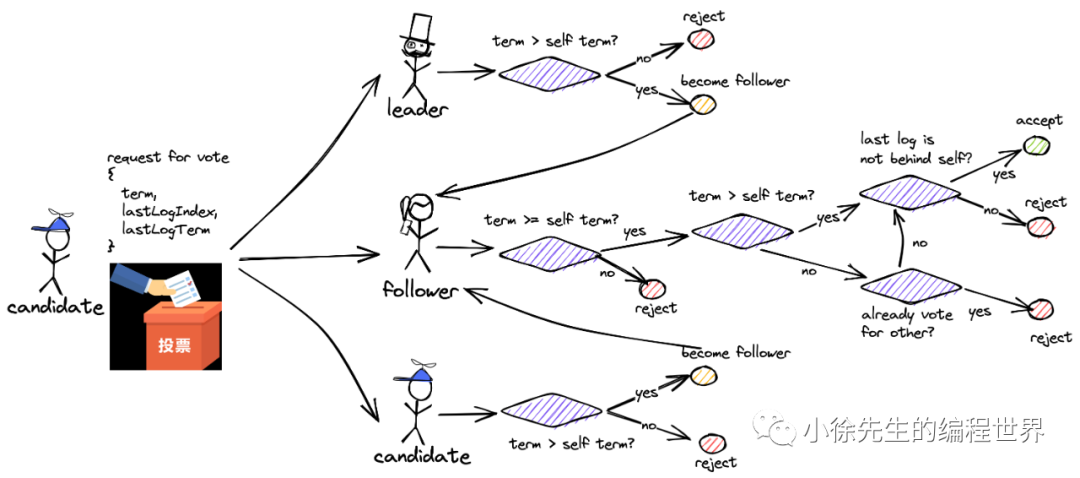
END
START
Basic
Raft 中如何将最终一致性提升到即时一致性
Back:
在写流程中,leader 不仅需要提交这笔写请求对应的预写日志,还需要确保将这笔日志应用到状态机中,才能给予客户端”请求成功“的 ack,以此保证读 leader 状态机时,能读取到最新的数据.
如果要求读流程满足即时一次性的要求,则要做一些额外的处理,通常有两种做法:
(1)appliedIndex 校验:每次 leader 处理写请求后,会把最晚一笔应用到状态机的日志索引 appliedIndex 反馈给客户端. 后续客户端和 follower 交互时,会携带 appliedIndex. 倘若 follower 发现自身的 appliedIndex 落后于客户端的 appliedIndex,说明本机存在数据滞后,则拒绝这笔请求,由客户端发送到其他节点进行处理.
(2)强制读主:follower 收到读请求时,也统一转发给 leader 处理. 只要 leader 处理写请求时,保证先写状态机,后给客户端响应,那么状态机的数据可以保证即时一致性. 但是这样的弊端就是 leader 的压力过大,其他 follower 节点只沦为备份数据副本的配角
强制读主有一个问题是在返回结果之前主需要先做一次身份确认,确认自己仍是集群的 leader,进一步降低了性能。注意,写请求不需要做额外的身份确认,因为写请求的提交之前本就会 proposal 给所有的机器
END
START
Basic
Raft 如何完成集群变更
Back:
记住一个点:集群变更期间的【集群变更 proposal 】和【写请求】都需要旧集群配置的多数派同意
Raft 的作者提供了两种解决思路。
- Joint Consensus
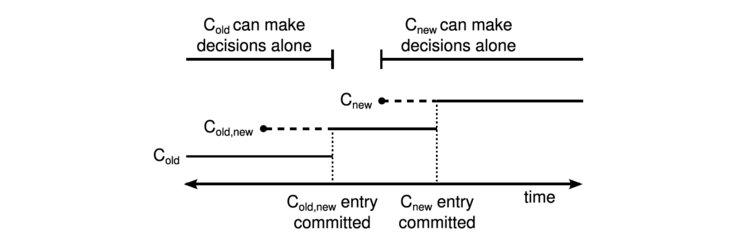
联合共识满足三个约束:
- 日志会被复制到新老配置的所有节点
- 新老配置的节点都可以被选举为领导者
- 选举和日志复制阶段需要在新老配置上面都超过半数才能被提交生效
- 单步成员变更
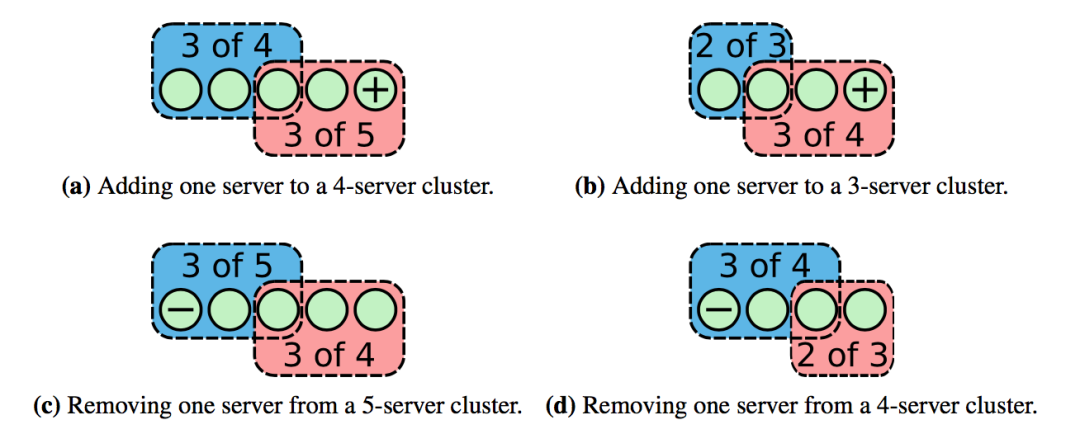
END
START
Basic
为什么新任 Leader 一定拥有旧 Leader 已提交的日志?
Back:
这是由两阶段提交和选举流程中的多数派原则保证的:
(1)只有被集群多数派完成同步的日志才会被 leader 提交;
(2)在选举流程中,节点只会把票投给日志进度不滞后于自身的 candidate;
(3)在竞选流程,candidate 需要获取多数派的赞同票才能胜任,成为新任 leader.
基于第(3)点可知,新任 leader 的日志进度一定能在竞选流程的多数派中出于不滞后的地位.
而在集群节点个数固定的情况下,本轮竞选流程的多数派和认可前任 leader 同步日志请求的多数派至少存在一个重复的节点,否则就违背了多数派的语义(集群半数以上),因此可以得知,新任 leader 一定拥有前任 leader 那笔被多数派认可的日志,即旧 leader 提交的日志.
END
START
Basic
Raft 中是否一项提议只需要被多数派通过就可以提交?
Back:
不是的
Raft 协议有一个非常重要的规定:当前 term 的 leader 至少需要完成一笔本 term 的写请求才能够执行提交动作
这个规定避免了在某些情况下已经被提交的日志发生回滚(Raft 决不允许这种情况)
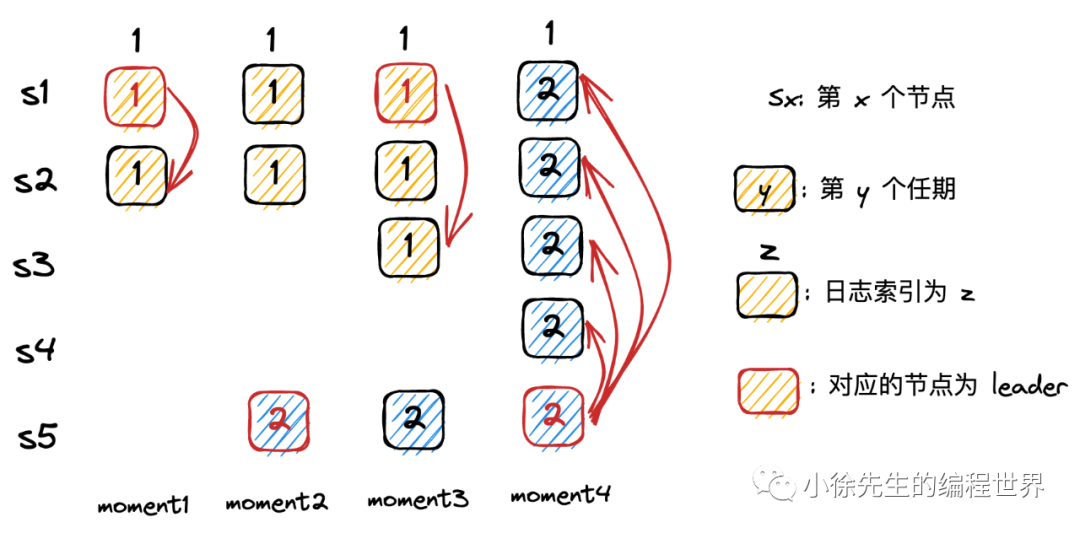
事实上,在工程实践上,通常每个 leader 上任之后,都会向集群广播同步一笔内容为空的日志,称之为 no-op. 只要这个请求被提交了,多数派也就写入了一遍当前任期的日志。
END
START
Basic
Raft 中如何解决网络分区引发的无意义选举问题?(预投票)
Back:
倘若集群产生网络分区,部分处于小分区的节点由于无法接收到 leader 的心跳,导致进入选举流程. 又因为网络分区问题,导致选举始终无法获得多数派的响应,最终 candidate 会无限自增 term. 直到网络恢复的那一刻,由于 candidate 异常的高 term,导致 leader 退位,集群进入新一轮的选举流程.
尽管小分区中的节点由于数据的滞后不可能在选举中胜出,最后必然是大分区中的节点胜任,节点数据的一致性依然可以得到保证. 但是这个无意义的选举过程同样会导致集群陷入暂不可用的阶段. 因此,我们可以通过这样的措施来避免这类无意义的选举:
每个 candidate 发起真实选举之前,会有一个提前试探的过程,试探机制是向集群所有节点发送请求,只有得到多数派的响应,证明自己不存在网络环境问题时,才会将竞选任期自增,并且发起真实的选举流程.
END
START
Basic
Raft如何保证客户端请求不丢失,不重复
Back:
不丢失:通过 ack 机制保证. 客户端超时未收到服务端的 ack,则会重发请求.
不重复:客户端记录写请求的序列号,与服务端交互时透传这个序列号. 最终由服务端的 leader 实现对相同序列号写请求的幂等去重.
END