虚函数
START
Basic
C++ 中析构函数为社么要定义为虚函数
Back:
在 C++ 中,如果一个类可能会被继承,并且其析构函数用于释放类对象所占用的资源,那么通常建议将析构函数定义为虚函数。
当基类的析构函数不是虚函数时,如果通过基类指针删除派生类对象,那么只会调用基类的析构函数,而不会调用派生类的析构函数。这可能导致派生类特有的资源没有被正确释放,从而造成内存泄漏或其他资源泄漏问题。
通过将析构函数定义为虚函数,可以解决上述问题。这样,当通过基类指针删除派生类对象时,会首先调用派生类的析构函数,然后再调用基类的析构函数。这样可以确保派生类的资源得到正确释放,避免资源泄漏问题。
END
START
Basic
什么是单例模式
Back:
单例模式是一种创建型设计模式,其核心思想是确保类在应用程序中只有一个实例,并提供一个全局访问点来访问该实例。单例模式通常被用来管理全局状态或共享资源,以确保在整个应用程序中只有一个唯一的实例被创建和使用。
单例模式通常包含以下几个关键要素:
- 私有的静态成员变量:用于存储单例实例的指针或引用。
- 私有的构造函数:用于防止外部代码直接实例化类对象。
- 公有的静态成员函数(或静态方法):用于获取单例实例的引用或指针,并且确保只有一个实例被创建。
#include <iostream>
class Singleton {
public:
// 公有的静态成员函数,用于获取单例实例
static Singleton& getInstance() {
static Singleton instance; // 延迟初始化
return instance;
}
// 其他成员函数
void doSomething() {
std::cout << "Singleton is doing something." << std::endl;
}
private:
// 私有的构造函数,防止外部实例化对象
Singleton() {}
// 禁用拷贝构造函数和赋值运算符
Singleton(const Singleton&) = delete;
Singleton& operator=(const Singleton&) = delete;
};
int main() {
// 获取单例实例并调用成员函数
Singleton& instance = Singleton::getInstance();
instance.doSomething();
return 0;
}
END
START
Basic
怎么解决懒汉模式中的线程安全问题
Back:
在懒汉模式(Lazy Initialization)中,单例实例是在首次使用时创建的。如果多个线程同时尝试访问未初始化的单例实例,可能会导致多个实例被创建,违反了单例模式的初衷。为了解决懒汉模式中的线程安全问题,可以使用一些线程安全的技术来确保只有一个实例被创建,常用的解决方案包括以下几种:
- 加锁
- 双重检查锁定(Double-Checked Locking)
- C++11 的局部静态变量
END
START
Basic
什么是工厂模式
Back:
工厂模式(Factory Pattern)是一种创建型设计模式,其目的是提供一种统一的方式来创建对象,而无需暴露对象的创建逻辑。工厂模式将对象的实例化过程封装在一个单独的工厂类中,客户端代码只需要通过工厂类来获取所需的对象,而不需要了解具体的实例化细节。
END
引用和指针
START
Basic
引用和指针的区别
Back:
-
内存管理:指针直接存储数据的内存地址,需要手动管理内存的分配和释放。而引用是一个别名,它引用了已经存在的变量或对象,不需要显式进行内存管理。
-
空值(null):指针可以具有空值(null),即指向无效或未初始化的内存地址。引用必须始终引用有效的对象或变量,不能为 null。
-
重新赋值:指针可以重新赋值为指向不同的内存地址,可以改变其所指向的对象或变量。引用在声明后不能重新赋值为引用其他对象或变量,它始终指向同一个对象或变量。
-
指向的类型:指针可以指向任何类型的数据,包括基本数据类型、自定义类型、数组等。引用在声明时必须指定引用的类型,并且只能引用与该类型兼容的对象或变量。
-
操作符:指针使用操作符 "*" 来访问指针所指向的对象或变量。引用不需要使用特殊的操作符,直接使用引用名即可访问引用的对象或变量。
-
传递方式:指针可以通过传值或传引用的方式传递给函数或方法。传递指针可以实现对原始数据的修改。引用作为函数参数时,实际上是传递了原始对象或变量的引用,可以通过引用对原始数据进行修改。
END
数据结构和算法
START
Basic
堆排序
Back:
构建堆(Heapify)是堆排序算法中的关键步骤之一,它的目标是将一个无序数组(或部分有序数组)转换成一个堆,通常是最大堆。构建堆的过程可以分为自底向上的方法(Bottom-up)和自顶向下的方法(Top-down)两种。
堆排序的底层数据结构是堆,而堆是一种特殊的树形数据结构,通常被实现为一个完全二叉树。堆具有以下几种性质:
-
完全二叉树结构:堆通常是一个完全二叉树,即除了最底层外,每一层都是满的,且最底层从左到右填充。这种结构可以通过数组来表示,节省了额外的指针空间。
-
最大堆性质:在最大堆中,父节点的值大于或等于其子节点的值。即对于任意节点 i,其父节点的值大于或等于节点 i 的值。
-
最小堆性质:在最小堆中,父节点的值小于或等于其子节点的值。即对于任意节点 i,其父节点的值小于或等于节点 i 的值。
-
堆的堆序性质:堆排序中,通常使用最大堆作为基础数据结构。即整个堆的根节点是堆中的最大元素。
自底向上的方法:
-
从最后一个非叶子节点开始:根据完全二叉树的性质,最后一个非叶子节点的索引为
(n/2)-1,其中 n 是数组的长度。 -
向上调整每个非叶子节点:对于每个非叶子节点,从其本身开始,依次与其左右子节点比较。如果发现当前节点的值小于其子节点的值(对于最大堆),则交换它们的位置。交换后,可能会破坏堆的性质,因此需要继续向下调整被交换的子节点,直到子树重新满足堆的性质为止。
-
重复此过程:继续向前移动,直到根节点。
END
C++11
START
Basic
变量模板
Back:
variadic template 是一种可以使用任意类型任意数量参数的模板
#include <iostream>
// Function to end the recursion of variadic template function
void
log() {
// This can be empty or used to print something that marks the end of output.
}
template <typename T, typename... Args>
void log(T first, Args... args)
{
std::cout << first;
if constexpr (sizeof...(args) > 0)
{
std::cout << " , ";
log(args...);
}
else
{
std::cout << std::endl; // New line for the last element
}
}
int main()
{
// Calling log() functio with 3 arguments
log(1, 4.3, "Hello");
// Calling log() functio with 4 arguments
log('a', "test", 78L, 5);
// Calling log() functio with 2 arguments
log("sample", "test");
return 0;
}
- Variadic template 通常和递归一起使用
- 注意递归的出口和参数
END
START
Basic
Delete 函数
Back:
class User {
int id;
std::string name;
public:
User(int userId, std::string userName) : id(userId), name(userName) {}
// Copy constructor is deleted
User(const User& obj) = delete;
// Assignment operator is deleted
User& operator=(const User& obj) = delete;
void display() {
std::cout << id << " ::: " << name << std::endl;
}
};
delete 函数常用的几种情况:
- 删除编译器自动添加的一些函数,例如 copy 和 assignment 构造函数,例如单例模式的实现就需要使用这个策略
- 在某些潜在类型转换会引发错误的情况下,将某些成员函数的特定类型参数实现删除可以避免
- 将 new 函数删掉可以防止类型在 heap 上被创建,保证其只会创建在栈上
- 删除模板实现上某些不需要的类型,防止这些类型的参数调用函数
END
START
Basic
Std:: Bind 是什么,有什么作用
Back:
std::bind 可以利用已有的函数创建新函数,用于固定已有函数的某些参数或者重新排列已有函数的参数列表
#include <algorithm>
#include <functional>
#include <iostream>
// For placeholders _1, _2, ...
using namespace std::placeholders;
int add(int first, int second) { return first + second; }
bool divisible(int num, int den) { return num % den == 0; }
int main() {
// Demonstrating binding and rearranging
auto new_add_func = std::bind(&add, 12, _1);
std::cout << new_add_func(5) << std::endl; // Outputs 17
auto mod_add_func = std::bind(&add, _2, _1);
std::cout << mod_add_func(12, 15) << std::endl; // Outputs 27
// Using bind with std::function
std::function<int(int)> mod_add_funcObj = std::bind(&add, 20, _1);
std::cout << mod_add_funcObj(15) <<
std::endl; // Outputs 35
// Counting multiples of 5 in an array
int arr[10] = {1, 20, 13, 4, 5, 6, 10, 28, 19, 15};
auto divisible_by_5 = std::bind(&divisible, _1, 5);
int count =
std::count_if(arr, arr + sizeof(arr) / sizeof(int), divisible_by_5);
std::cout << count << std::endl; // Outputs number of elements divisible by 5
return 0;
}
END
START
Basic
智能指针
Back:
传统的 C++内存管理只能手动地使用 new 和 delete 来申请和释放内存,这对于一个有着非常多变量的大型项目来说是灾难
智能指针的出现就是为了解决这样的问题的,它是普通指针的封装,它能够在变量离开作用域的时候自动释放。这种自动内存管理模拟了堆栈变量的便利性,并通过降低内存泄露和悬空指针的风险,确保代码更加安全。
智能指针有三种类型,都被包含于 <memory> 这个头文件中
std::unique_ptr:不能够被 copy,保证同一时间一个内存资源只能有一个所有者std::shared_ptr:对于同一个内存可以有多个所有者,它们使用 reference counting 来追踪有多少个所有者,内存只在最后一个shared_ptr被销毁时释放std::weak_ptr:这些是没有所有权的指针指向被shared_ptr管理的对象,它们不会影响引用计数器,通常被用来打破由shared_ptr引起的循环引用
unique_ptr
unique_ptr 的好处有:
- 单一的所有权关系
- 自动内存销毁
// `unique_ptr` 的延迟初始化
std::unique_ptr<int> ptrObj(nullptr);
ptrObj.reset(new int());
// `unique_ptr` 转换为raw指针
std::unique_ptr<int> intPtr(new int(4));
*intPtr = 42
int *rawIntPtr = intPtr.get();
make_unique<T>() 是 C++标准库提供的一个用于创建 unique_ptr 的方法,它可以让程序员不再需要显式调用 new,保证了程序的简洁无误
它的用法如下:
auto ptrObj = std::make_unique<DATA_TYPE>(constructor_arguments);
它的好处如下:
- 它提供了非常强大的正确性保证,它申请内存和创建对象是原子的,如果使用 new 创建然后在构造智能指针的过程中发生错误则有可能造成内存泄漏
- 代码简洁
- 仅仅传递参数,它会将参数直接传递给构造函数
- 减少类型代码重复,使用 new 的话需要重复一次创建的类型的代码
unique_ptr 是不允许被 copy 的,也就是说,以下的代码不会通过编译:
// unique_ptr pointing to an int with value 12
std::unique_ptr<int> ptrObj(new int(12));
// Attempting to copy will fail at compile time
std::unique_ptr<int> anotherPtr = ptrObj; // This will not compile
但是你可以通过 std::move 来转移 unique_ptr 的所有权
因此在将 unique_ptr 作为参数传递的时候,必须使用 std::move,将所有权移交给函数的参数,在所有权移交之后,原有的 unique_ptr 变量指向 nullptr
#include <iostream>
#include <memory>
void processValueunique_ptr<int> ptr
{
// Print information about the ptr (in our case, an int value)
std::cout << "Integer value: " << *ptr << std::endl;
}
int main()
{
std::unique_ptr<int> ptrObj = std::make_unique<int>(10);
// This line would cause a compile-time error
// Because we can not create a copy of unique pointer
// processValue(ptrObj);
// We can move unique_ptr object
processValuemove(ptrObj); // This is correct
// Once moved, unique_ptr object is empty and internally points to null
if (!ptrObj)
{
std::cout << "ptrObj is now null." << std::endl;
}
// We can move unique_ptr object
processValuemake_unique<int>(30); // This is correct
return 0;
}
reset() 方法可以让你主动释放一个 unique_ptr 所拥有的资源,并让这个 unique_ptr 值为 nullptr
根据 C++的 Return Value Optimization(RVO)原则,可以直接返回一个 unique_ptr ,会自动进行所有权转移
使用 make_unique 创建数组的时候(C++17 之后),不能够在声明的时候初始化,而需要在之后进行初始化:
#include <iostream>
#include <memory>
int main()
{
auto arr = std::make_unique<int[]>(3);
// Initialize elements (not directly via make_unique due to limitations)
for (int i = 0; i < 3; ++i)
{
arr[i] = (i + 1) * 100;
}
// Iterate over the array elements & Print them
for (int i = 0; i < 3; ++i)
{
std::cout << arr[i] << " ";
}
std::cout << std::endl;
return 0;
}
shared_ptr
由于 shared_ptr 可以与继承层次结构一起使用,因此在处理指向派生实例的基类指针集合时,可以实现多态行为。
shared_ptr 通常在以下场景中被使用:
- 简化复杂的数据结构:例如树和图中,当一个节点需要被多个元素共享的时候
- 线程安全:多线程可以同时对它们自己的
shared_ptr实例进行创建和销毁而不用额外的同步 - 异常安全:
shared_ptr不会在异常发生的时候产生任何的内存泄漏 - 解耦:程序的某部分可以使用一个对象而不用担心其他部分也在使用它
但同时,使用shared_ptr也会产生一些问题,例如: - 额外的开销:引用计数器带来的开销
- 可能会产生循环引用,这需要用
weak_ptr来解决
可以使用 == 或者 != 来比较两个 shared_ptr,当两者指向的资源对象相等的时候等式成立
#include <iostream>
#include <memory> // We need to include this for shared_ptr
int main() {
// Creating a shared_ptr through make_shared
std::shared_ptr < int > p1 = std::make_shared < int > ();
* p1 = 78;
std::cout << "p1 = " << * p1 << std::endl;
// Shows the reference count
std::cout << "p1 Reference count = " << p1.use_count() << std::endl;
// Second shared_ptr object will also point to same pointer internally
// It will make the reference count to 2.
std::shared_ptr < int > p2(p1);
// Shows the reference count
std::cout << "p2 Reference count = " << p2.use_count() << std::endl;
std::cout << "p1 Reference count = " << p1.use_count() << std::endl;
// Comparing smart pointers
if (p1 == p2) {
std::cout << "p1 and p2 are pointing to same pointer\n";
}
std::cout << "Reset p1 " << std::endl;
p1.reset();
// Reset the shared_ptr, in this case it will not point to any Pointer internally
// hence its reference count will become 0.
std::cout << "p1 Reference Count = " << p1.use_count() << std::endl;
// Reset the shared_ptr, in this case it will point to a new Pointer internally
// hence its reference count will become 1.
p1.reset(new int(11));
std::cout << "p1 Reference Count = " << p1.use_count() << std::endl;
// Assigning nullptr will de-attach the associated pointer and make it to point null
p1 = nullptr;
std::cout << "p1 Reference Count = " << p1.use_count() << std::endl;
if (!p1) {
std::cout << "p1 is NULL" << std::endl;
}
return 0;
}
shared_ptr 在初始化的时候可以额外接受一个参数,作为自定义的解构函数,当这个 shared_ptr 离开作用域的时候,会调用这个自定义的解构函数
#include <iostream>
#include <memory>
struct Sample {
Sample() {
std::cout << "Sample CONSTRUCTOR\n";
}
~Sample() {
std::cout << "Sample DESTRUCTOR\n";
}
};
// Function that calls 'delete[]' on the received pointer
void deleter(Sample * x) {
std::cout << "Custom DELETER FUNCTION CALLED\n";
delete[] x;
}
int main() {
// Creating a shared_ptr with custom deleter
std::shared_ptr < Sample > p3(new Sample[12], deleter);
return 0;
}
不要使用 shared_ptr 的情况
- 使用同一个 raw 指针初始化若干个
shared_ptr(double-deletion) - 使用栈空间初始化智能指针(智能指针会尝试 delete 这个空间)
shared_ptr没有[],++,--操作符,且对 array 的支持不太完善
weak_ptr
#include <iostream>
#include <memory>
class Node {
int value;
public: std::shared_ptr < Node > leftPtr;
std::shared_ptr < Node > rightPtr;
std::weak_ptr < Node > parentPtr; // Changed from shared_ptr to weak_ptr
Node(int val): value(val) {
std::cout << "Constructor" << std::endl;
}
~Node() {
std::cout << "Destructor" << std::endl;
}
};
int main() {
std::shared_ptr < Node > root = std::make_shared < Node > (4);
root - > leftPtr = std::make_shared < Node > (2);
root - > leftPtr - > parentPtr = root;
root - > rightPtr = std::make_shared < Node > (5);
root - > rightPtr - > parentPtr = root;
// Outputs to help visualize reference counts
std::cout << "root reference count = " << root.use_count() << std::endl;
std::cout << "root->leftPtr reference count = " << root - > leftPtr.use_count() << std::endl;
std::cout << "root->rightPtr reference count = " << root - > rightPtr.use_count() << std::endl;
std::cout << "root->rightPtr->parentPtr reference count (via lock) = " << root - > rightPtr - > parentPtr.lock().use_count() << std::endl;
std::cout << "root->leftPtr->parentPtr reference count (via lock) = " << root - > leftPtr - > parentPtr.lock().use_count() << std::endl;
return 0;
}
END
START
Basic
右值引用
Back:
C++11 的 move 语义是为了减少将亡值的开销的,例如使用工厂模式创建一个包含一个数组的 Container 类型,通常会有以下的写法:
// Create am object of Container and return
Container getContainer()
{
Container obj;
return obj;
}
int main() {
// Create a vector of Container Type
std::vector<Container> vecOfContainers;
//Add object returned by function into the vector
vecOfContainers.push_back(getContainer());
return 0;
}
这里实际上进行了两次拷贝,我们在 getContainer() 中创建了一个将亡值,然后通过拷贝构造函数赋值给了新的变量,随后将亡值被销毁
我们可以用 move 语义和右值引用来解决这个问题,我们可以用右值引用来重载构造函数甚至函数
move 构造函数接受一个右值引用作为一个参数(相对的的,拷贝构造函数接受一个常左值引用)
Container(Container && obj)
{
// Just copy the pointer
m_Data = obj.m_Data;
// Set the passed object's member to NULL
obj.m_Data = NULL;
std::cout<<"Move Constructor"<<std::endl;
}
类似的,我们还可以重载 = 赋值操作符
#include <iostream>
#include <vector>
class Container {
int * m_Data;
public: Container() {
//Allocate an array of 20 int on heap
m_Data = new int[20];
std::cout << "Constructor: Allocation 20 int" << std::endl;
}
~Container() {
if(m_Data) {
delete[] m_Data;
m_Data = NULL;
}
}
//Copy Constructor
Container(const Container & obj) {
//Allocate an array of 20 int on heap
m_Data = new int[20];
//Copy the data from passed object
for(int i = 0; i < 20; i++) m_Data[i] = obj.m_Data[i];
std::cout << "Copy Constructor: Allocation 20 int" << std::endl;
}
//Assignment Operator
Container & operator = (const Container & obj) {
if(this != & obj) {
//Allocate an array of 20 int on heap
m_Data = new int[20];
//Copy the data from passed object
for(int i = 0; i < 20; i++) m_Data[i] = obj.m_Data[i];
std::cout << "Assigment Operator: Allocation 20 int" << std::endl;
}
}
// Move Constructor
Container(Container && obj) {
// Just copy the pointer
m_Data = obj.m_Data;
// Set the passed object's member to NULL
obj.m_Data = NULL;
std::cout << "Move Constructor" << std::endl;
}
// Move Assignment Operator
Container & operator = (Container && obj) {
if(this != & obj) {
// Just copy the pointer
m_Data = obj.m_Data;
// Set the passed object's member to NULL
obj.m_Data = NULL;
std::cout << "Move Assignment Operator" << std::endl;
}
}
};
// Create am object of Container and return
Container getContainer() {
Container obj;
return obj;
}
int main() {
// Create a vector of Container Type
std::vector < Container > vecOfContainers;
//Add object returned by function into the vector
vecOfContainers.push_back(getContainer());
Container obj;
obj = getContainer();
return 0;
}
注意这里的函数会返回一个右值因此出触发的是 move 构造函数和 move 赋值操作符
END
START
Basic
左值和右值的区别
Back:
左值是一切可以取地址的对象,我们可以对左值使用 & 取地址
一切不为左值的对象就是右值,右值通常是一个不会持久化的暂时的单一表达式
右值的修改情况:
- 不能修改基本类型的右值
- 能修改用户定义类型的右值:连续的函数调用
#include <iostream>
class Person {
int mAge;
public: Person() {
mAge = 10;
}
void incrementAge() {
mAge = mAge + 1;
}
};
Person getPerson() {
return Person();
}
int main() {
// Person * personPtr = &getPerson();
getPerson().incrementAge();
return 0;
}
END
START
Basic
Const 关键字
Back:
// 类
class A
{
private:
const int a; // 常对象成员,可以使用初始化列表或者类内初始化
public:
// 构造函数
A() : a(0) { };
A(int x) : a(x) { }; // 初始化列表
// const可用于对重载函数的区分
int getValue(); // 普通成员函数
int getValue() const; // 常成员函数,不得修改类中的任何数据成员的值
};
void function()
{
// 对象
A b; // 普通对象,可以调用全部成员函数
const A a; // 常对象,只能调用常成员函数
const A *p = &a; // 指针变量,指向常对象
const A &q = a; // 指向常对象的引用
// 指针
char greeting[] = "Hello";
char* p1 = greeting; // 指针变量,指向字符数组变量
const char* p2 = greeting; // 指针变量,指向字符数组常量(const 后面是 char,说明指向的字符(char)不可改变)
char* const p3 = greeting; // 自身是常量的指针,指向字符数组变量(const 后面是 p3,说明 p3 指针自身不可改变)
const char* const p4 = greeting; // 自身常量的指针,指向字符数组常量
}
// 函数
void function1(const int Var); // 传递过来的参数在函数内不可变
void function2(const char* Var); // 参数指针所指内容为常量
void function3(char* const Var); // 参数指针为常量
void function4(const int& Var); // 引用参数在函数内为常量
// 函数返回值
const int function5(); // 返回一个常数
const int* function6(); // 返回一个指向常量的指针变量,使用:const int *p = function6();
int* const function7(); // 返回一个指向变量的常指针,使用:int* const p = function7();
- const type* 是常量指针
- type* const 是指针常量(指针本身不可变)
宏定义 #define |
const 常量 |
|---|---|
| 宏定义,相当于字符替换 | 常量声明 |
| 预处理器处理 | 编译器处理 |
| 无类型安全检查 | 有类型安全检查 |
| 不分配内存 | 要分配内存 |
| 存储在代码段 | 存储在数据段 |
可通过 #undef 取消 |
不可取消 |
END
START
Basic
static 关键字
Back:
- 修饰普通变量,修改变量的存储区域和生命周期,使变量存储在静态区,在 main 函数运行前就分配了空间,如果有初始值就用初始值初始化它,如果没有初始值系统用默认值初始化它。
- 修饰普通函数,表明函数的作用范围,仅在定义该函数的文件内才能使用。在多人开发项目时,为了防止与他人命名空间里的函数重名,可以将函数定位为 static。
- 修饰成员变量,修饰成员变量使所有的对象只保存一个该变量,而且不需要生成对象就可以访问该成员。
- 修饰成员函数,修饰成员函数使得不需要生成对象就可以访问该函数,但是在 static 函数内不能访问非静态成员。
END
START
Basic
虚函数(virtual)可以是内联函数(inline)吗?
Back:
- 内联函数在代码展开时,会做安全检查或自动类型转换
- 是否内联,程序员不可控。内联函数只是对编译器的建议,是否对函数内联,决定权在于编译器。
- 虚函数可以是内联函数,内联是可以修饰虚函数的,但是当虚函数表现多态性的时候不能内联。
- 内联是在编译期建议编译器内联,而虚函数的多态性在运行期,编译器无法知道运行期调用哪个代码,因此虚函数表现为多态性时(运行期)不可以内联。
inline virtual唯一可以内联的时候是:编译器知道所调用的对象是哪个类(如Base::who()),这只有在编译器具有实际对象而不是对象的指针或引用时才会发生。
END
START
Basic
volatile 关键字
Back:
- volatile 关键字是一种类型修饰符,用它声明的类型变量表示可以被某些编译器未知的因素(操作系统、硬件、其它线程等)更改。所以使用 volatile 告诉编译器不应对这样的对象进行优化。
- volatile 关键字声明的变量,每次访问时都必须从内存中取出值(没有被 volatile 修饰的变量,可能由于编译器的优化,从 CPU 寄存器中取值)
- const 可以是 volatile (如只读的状态寄存器)
- 指针可以是 volatile
END
START
Basic
C++ 中 struct 和 class
Back:
- 最本质的一个区别就是默认的访问控制
- 默认的继承访问权限。struct 是 public 的,class 是 private 的。
- struct 作为数据结构的实现体,它默认的数据访问控制是 public 的,而 class 作为对象的实现体,它默认的成员变量访问控制是 private 的。
END
START
Basic
explicit 关键字
Back:
- explicit 修饰构造函数时,可以防止隐式转换和复制初始化
- explicit 修饰转换函数时,可以防止隐式转换,但 按语境转换 除外
struct A
{
A(int) { }
operator bool() const { return true; }
};
struct B
{
explicit B(int) {}
explicit operator bool() const { return true; }
};
void doA(A a) {}
void doB(B b) {}
int main()
{
A a1(1); // OK:直接初始化
A a2 = 1; // OK:复制初始化
A a3{ 1 }; // OK:直接列表初始化
A a4 = { 1 }; // OK:复制列表初始化
A a5 = (A)1; // OK:允许 static_cast 的显式转换
doA(1); // OK:允许从 int 到 A 的隐式转换
if (a1); // OK:使用转换函数 A::operator bool() 的从 A 到 bool 的隐式转换
bool a6(a1); // OK:使用转换函数 A::operator bool() 的从 A 到 bool 的隐式转换
bool a7 = a1; // OK:使用转换函数 A::operator bool() 的从 A 到 bool 的隐式转换
bool a8 = static_cast<bool>(a1); // OK :static_cast 进行直接初始化
B b1(1); // OK:直接初始化
B b2 = 1; // 错误:被 explicit 修饰构造函数的对象不可以复制初始化
B b3{ 1 }; // OK:直接列表初始化
B b4 = { 1 }; // 错误:被 explicit 修饰构造函数的对象不可以复制列表初始化
B b5 = (B)1; // OK:允许 static_cast 的显式转换
doB(1); // 错误:被 explicit 修饰构造函数的对象不可以从 int 到 B 的隐式转换
if (b1); // OK:被 explicit 修饰转换函数 B::operator bool() 的对象可以从 B 到 bool 的按语境转换
bool b6(b1); // OK:被 explicit 修饰转换函数 B::operator bool() 的对象可以从 B 到 bool 的按语境转换
bool b7 = b1; // 错误:被 explicit 修饰转换函数 B::operator bool() 的对象不可以隐式转换
bool b8 = static_cast<bool>(b1); // OK:static_cast 进行直接初始化
return 0;
}
END
START
Basic
decltype 关键字
Back:
decltype 关键字用于检查实体的声明类型或表达式的类型及值分类。
// 尾置返回允许我们在参数列表之后声明返回类型
template <typename It>
auto fcn(It beg, It end) -> decltype(*beg)
{
// 处理序列
return *beg; // 返回序列中一个元素的引用
}
// 为了使用模板参数成员,必须用 typename
template <typename It>
auto fcn2(It beg, It end) -> typename remove_reference<decltype(*beg)>::type
{
// 处理序列
return *beg; // 返回序列中一个元素的拷贝
}
END
START
Basic
initializer_list 列表初始化
Back:
用花括号初始化器列表初始化一个对象,其中对应构造函数接受一个 std::initializer_list 参数.
#include <iostream>
#include <vector>
#include <initializer_list>
template <class T>
struct S {
std::vector<T> v;
Sinitializer_list<T> l) : v(l {
std::cout << "constructed with a " << l.size() << "-element list\n";
}
void appendinitializer_list<T> l {
v.insert(v.end(), l.begin(), l.end());
}
std::pair<const T*, std::size_t> c_arr() const {
return {&v[0], v.size()}; // 在 return 语句中复制列表初始化
// 这不使用 std::initializer_list
}
};
template <typename T>
void templated_fn(T) {}
int main()
{
S<int> s = {1, 2, 3, 4, 5}; // 复制初始化
s.append({6, 7, 8}); // 函数调用中的列表初始化
std::cout << "The vector size is now " << s.c_arr().second << " ints:\n";
for (auto n : s.v)
std::cout << n << ' ';
std::cout << '\n';
std::cout << "Range-for over brace-init-list: \n";
for (int x : {-1, -2, -3}) // auto 的规则令此带范围 for 工作
std::cout << x << ' ';
std::cout << '\n';
auto al = {10, 11, 12}; // auto 的特殊规则
std::cout << "The list bound to auto has size() = " << al.size() << '\n';
// templated_fn({1, 2, 3}); // 编译错误!“ {1, 2, 3} ”不是表达式,
// 它无类型,故 T 无法推导
templated_fn<std::initializer_list<int>>({1, 2, 3}); // OK
templated_fn<std::vector<int>>({1, 2, 3}); // 也 OK
}
END
START
Basic
虚函数指针、虚函数表
Back:
- 虚函数指针:在含有虚函数类的对象中,指向虚函数表,在运行时确定。
- 虚函数表:在程序只读数据段(
.rodata section,见:目标文件存储结构),存放虚函数指针,如果派生类实现了基类的某个虚函数,则在虚表中覆盖原本基类的那个虚函数指针,在编译时根据类的声明创建。
END
START
Basic
申请内存有哪些方法,有什么区别
Back:
- malloc:申请指定字节数的内存。申请到的内存中的初始值不确定。
- calloc:为指定长度的对象,分配能容纳其指定个数的内存。申请到的内存的每一位(bit)都初始化为 0。
- realloc:更改以前分配的内存长度(增加或减少)。当增加长度时,可能需将以前分配区的内容移到另一个足够大的区域,而新增区域内的初始值则不确定。
- alloca:在栈上申请内存。程序在出栈的时候,会自动释放内存。但是需要注意的是,alloca 不具可移植性, 而且在没有传统堆栈的机器上很难实现。alloca 不宜使用在必须广泛移植的程序中。C99 中支持变长数组 (VLA),可以用来替代 alloca。
- new / new[]:完成两件事,先底层调用 malloc 分配了内存,然后调用构造函数(创建对象)。
- delete/delete[]:也完成两件事,先调用析构函数(清理资源),然后底层调用 free 释放空间。
- new 在申请内存时会自动计算所需字节数,而 malloc 则需我们自己输入申请内存空间的字节数。
END
START
Basic
如何定义一个只能在堆上(栈上)生成对象的类?
Back:
只能在堆上的类
方法:将析构函数设为私有
C++是静态绑定的,编译器管理栈上对象的生命周期,编译器在为类对象分配栈空间时,会先检查类的析构函数的访问性。若析构函数函数不可访问,则不能在栈上创建
只能在栈上
方法:将 new 和 delete 重载为私有
在堆上生成对象,使用 new 关键词操作,其过程分为两阶段:第一阶段,使用 new 在堆上寻找可用内存,分配给对象;第二阶段,调用构造函数生成对象。将 new 操作设置为私有,那么第一阶段就无法完成,就不能够在堆上生成对象。
END
START
Basic
强制类型转换符
Back:
static_cast:用于非多态类型的转换,不执行运行时类型检查,通常用于转换简单数值类型dynamic_cast:用于多态类型的转换,有运行时间擦好,对不明确的指针将返回nullptr,表示转换失败const_cast:用于删除 const、volatile 和__unaligned 特性(const int 转换为 int)reinterpret_cast:用于位的简单重新解释
END
START
Basic
继承权限问题?
Back:
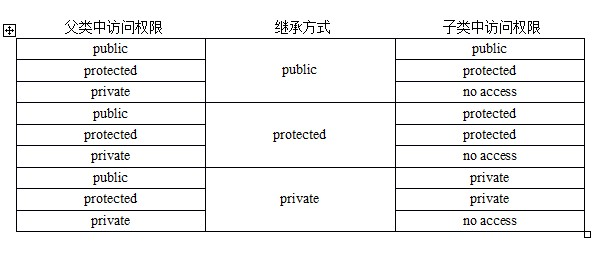
END
START
Basic
局部静态变量有什么用?
Back:
局部静态变量位于内存中的静态存储区,未经初始化的局部静态变量会自动初始化为0。但是局部静态变量的作用于还是还是局部作用于,定义它的函数或者代码块结束的时候,作用于也随之结束。但是该变量值不会被销毁,而是在内存中驻留下来,知道程序全部结束,这个驻留的值我们不能访问她。
对于全局变量的构造和析构,肯定是排在首位的。
而对于局部静态变量,程序首次执行到局部静态变量的定义处时才发出构造,其构造和析构都取决于程序的执行顺序。很显然,对于分布在程序各处的静态局部变量,其构造顺序取决于它们在程序的实际执行路径上的先后顺序,而析构顺序则正好与之相反。这就有两个问题:
- 一方面是因为程序的实际执行路径有多个决定因素(例如基于消息驱动模型的程序和多线程程序),有时是不可预知的;
- 另一方面是因为局部静态变量分布在程序代码各处,彼此直接没有明显的关联,很容易让开发者忽略它们之间的这种关系(这是最坑的地方)。
所以我们应该尽量少使用静态变量。
END
START
Basic
static 初始化时机和线程安全问题
Back:
在 C 语言中:
静态局部变量和全局变量一样,数据都存放在全局区域,所以在主程序之前,编译器已经为其分配好了内存,在编译阶段分配好了内存之后就进行初始化,在程序运行结束时变量所处的全局内存会被回收。所以在c语言中无法使用变量对静态局部变量进行初始化。
在 C++中:
- 编译初始化也叫静态初始化。对全局变量和const类型的初始化主要是,叫做zero initialization 和 const initialization,静态初始化在程序加载的过程中完成。从具体实现上看,zero initialization 的变量会被保存在 bss 段,const initialization 的变量则放在 data 段内,程序加载即可完成初始化,这和 c 语言里的全局变量静态变量初始化基本是一致的。其次全局类对象也是在编译器初始化。
- 动态初始化也叫运行时初始化。主要是指需要经过函数调用才能完成的初始化或者是类的初始化,一般来说是局部静态类对象的初始化和局部静态变量的初始化。
C语言中非局部静态变量一般在main执行之前的静态初始化过程中分配内存并初始化,可以认为是线程安全的;C++11标准针规定了局部静态变量初始化是线程安全的。这里的线程安全指的是:一个线程在初始化 m 的时候,其他线程执行到 m 的初始化这一行的时候,就会挂起而不是跳过。
END
START
Basic
引用和指针的关系
Back:
在底层,引用变量由指针按照指针常量的方式实现。两者都必须在声明的时候完成初始化
(1)在内存中都是占用 4 个字节(32 bits 系统中)的存储空间,存放的都是被引用对象的地址,都必须在定义的同时进行初始化。
(2)指针常量本身(以 p 为例)允许寻址,即 &p 返回指针常量(常变量)本身的地址,被引用对象用 *p 表示;引用变量本身(以 r 为例)不允许寻址,&r 返回的是被引用对象的地址,而不是变量 r 的地址(r 的地址由编译器掌握,程序员无法直接对它进行存取),被引用对象直接用 r 表示。
(3)凡是使用了引用变量的代码,都可以转换成使用指针常量的对应形式的代码,只不过书写形式上要繁琐一些。反过来,由于对引用变量使用方式上的限制,使用指针常量能够实现的功能,却不一定能够用引用来实现。
END
START
Basic
左值和右值?
Back:
- C++中,左值是
locator value的缩写,也就是说 lvalue 对应了一块内存地址 - 引用能绑定到左值但唯有const的引用能绑定到右值的规则
- 对表达式求职可以得到一个结果,这个结果有两个属性:(1)类型,例如
int、string等。(2)值类别。 自C++11开始,表达式的值分为左值(lvalue, left value):具名且不可被移动将亡值(xvalue, expiring value):具名且可被移动纯右值(pvalue, pure ravlue):不具名且可被移动泛左值(glvalue, generalized lvalue):lvalue 和 xvalue右值(rvalue, right value):可被移动的表达式,prvalue 和 xvalue 都属于 rvalue
- 五种类别基于表达式的两个特征:
- 具名 (identity):可以确定表达式是否与另一个表达式指代同一个实体,例如通过比较它们所标识的对象或函数(直接或间接获得的)地址
- 可被移动 (movable):移动构造函数、移动赋值运算符实现了移动语义的其他函数重载能够绑定于这个表达式
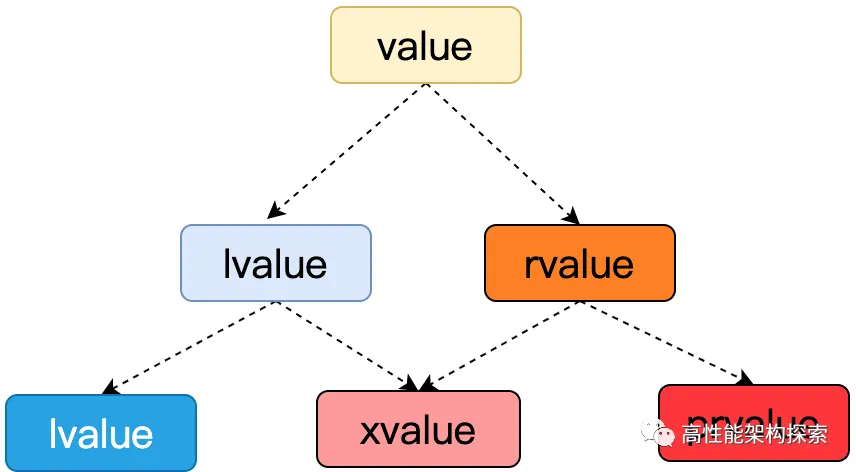
- 对于一个表达式,凡是对其取地址(&)操作可以成功的都是左值
- 字面值或者函数返回的非引用都是纯右值
- 将亡值可以理解为通过“盗取”其他变量内存空间的方式获取到的值(通过右值引用来续命)
- 返回右值引用的函数的调用表达式,如
static_cast<T&&>(t);该表达式得到一个 xvalue - 转换为右值引用的转换函数的调用表达式,如:
std::move(t)(将左值转换为右值,借助移动语义来优化性能)、static_cast<T&&>(t)
- 返回右值引用的函数的调用表达式,如
- 一些例子(反直觉)
- 前置自增(减)是左值,后置自增(减)是纯右值
- 算术表达式是纯右值
- 解引用是左值 (
&(*p)合法),取地址是纯右值 (&a是一个字面量) - 字符串字面值是左值(对字符串字面值可以取地址,因为它的实现是一个 char 数组,存储在数据段)
- 右值引用可能是左值也可能是右值,因此右值引用可以作为一个参数的路由,借助std::forward实现完美转发,我们可以结合完美转发和移动语义来实现一个泛型的工厂函数,这个工厂函数可以创建所有类型的对象。具体实现如下:
template<typename… Args>
T* Instance(Args&&… args)
{
return new Tforward<Args >(args)…;
}
END
START
Basic
深浅拷贝和“指针悬挂”问题
Back:
在未定义显示拷贝构造函数的情况下,系统会调用默认的拷贝函数——即浅拷贝,它能够完成成员的一一复制。
当数据成员中没有指针时,浅拷贝是可行的;
但当数据成员中有指针时,会出问题。如果没有自定义拷贝构造函数,会调用默认拷贝构造函数,这样就会调用两次析构函数。第一次析构函数delete了内存,第二次的就指针悬挂了。所以,此时,必须采用深拷贝。
深拷贝与浅拷贝的区别就在于深拷贝会在堆内存中另外申请空间来储存数据,从而也就解决了指针悬挂的问题。简而言之,当数据成员中有指针时,必须要用深拷贝。
右值引用和移动语句就是为了来解决这样的问题的
class A
{
public:
A() :m_ptr(new int(0)){}
A(const A& a):m_ptr(new int(*a.m_ptr)) //深拷贝的拷贝构造函数
{
cout << "copy construct" << endl;
}
A(A&& a) :m_ptr(a.m_ptr)
{
a.m_ptr = nullptr;
cout << "move construct" << endl;
}
~A(){ delete m_ptr;}
private:
int* m_ptr;
};
int main(){
A a = Get(false);
}
输出:
construct
move construct
move construct
END
START
Basic
C++的所有构造函数
Back:
- 默认构造函数:编译器会默认生成一个无参的构造函数
- 一般构造函数:一个类可以拥有多个一般构造函数,参数的类型和顺序不同就被认为是不同的构造函数(多态)
- 拷贝构造函数:拷⻉构造函数的函数参数为对象本身的引用,编译器会自动创建一个默认的拷贝构造函数,但是当成员中含有指针的时候,默认对指针对象进行浅拷贝,这种行为是非常危险的,这就是著名的指针悬挂,有可能会造成 double delete,因此要使用深拷贝,但这样是非常昂贵的
- 移动构造函数:移动构造函数主要是为了进行资源的转移,例如将指针的所有权移交到新的实例中,可以将指针进行浅拷贝,然后再将原有的指针置为 NULL
- 赋值构造函数:
=运算符的重载,分为拷贝赋值构造函数和移动赋值构造函数 - 类型转换构造函数:不想要隐式转换,用explict关键字修饰
END
START
Basic
构造函数和析构函数能否抛出异常?
Back:
构造函数是可以抛出异常的
- C++只会析构已经完成构造的函数,因此构造中间抛出异常的实例不会掉用析构函数
- 抛出异常会移交程序的控制权,成员对象会被释放,但是申请的内存得不到释放,会造成内存泄漏
析构函数不能也不应该抛出异常
C++的异常处理有负责清理出现异常的资源,并且通常是由析构函数来完成这个工作的,因此析构函数就是异常处理的一部分,因此: - 析构函数得不到执行,可能会导致部分资源无法被释放
- 异常处理会进行栈展开,掉用栈构造好的对象的析构函数,然后析构函数又抛出异常,这样会导致程序崩溃
END
START
Basic
new 和 malloc 的区别
Back:
- 概念上的区别
malloc/free是C++/C语言的标准库函数,而new/delete是C++的运算符。因此malloc仅仅只分配内存,而不会进行初始化类成员的工作,new不止分配内存,而且还是调用类的构造函数。 - 返回类型的安全性
new操作符内存分配成功时候,返回的是对象类型的指针,不需要进行类型转换,从这个角度来说比较安全
malloc内存分配成功则返回void*类型(泛型指针),必须通过强制类型转换将void*转换成需要的类型。 - 分配失败后返回值也不同
malloc失败,会返回空指针。
new失败,默认是抛出异常,要捕获异常bad_alloc
END