OceanBase 核心特性
- 高可用:三地五中心
- 高兼容:兼容 Oracle 和 MySQL
- 水平拓展:支持集群节点超过数千个,单集群最大数据量超过 3 PB,最大单表行数达数万亿级
- 低成本:基于 LSM-Tree 的高压缩引擎
- 实时 HTAP:“一份数据”的多个副本可以存储成多种形态
- 安全可靠
OceanBase 系统架构
采用无共享分布式集群架构,各个节点之间完全对等,每个节点都有自己的 SQL 引擎、存储引擎、事务引擎,运行在普通 PC 服务器组成的集群之上
- 接入层:数据库代理 ODP
- SQL 层:Parser、Resolver、Trasformer、Optimizer、Code Generator、Executor,分为本地、远程和分布式计划,使用并行查询技术
- 事务层:保证单个日志流和多个日志流操作提交的原子性,保证了并发事务之间的多版本隔离能力
- 两阶段提交(WAL、commit)
- GTS 服务提供全局的版本号机制,每个事务都会持久化一个时间戳到日志流中,事务内所有修改的数据都以此提交版本号标记
- 均衡层:均衡层会通过日志流的分裂和合并操作,配合日志流副本的移动,实现均衡
- 复制层:使用日志流持久化 Redo 日志,日志流的多个副本会分布在不同的可用区中
- 存储层:以 Tablet 为单位的分层 LSM-Tree 结构:
- MemTable:内存
- L0 层 SSTable
- L1 层 SSTable
- Major SStable:业务低峰期,系统会将所有的 Memtable 和 SSTable 合并成一个 Major SSTable
- 多租户层:资源单元(CPU、内存),隔离实例
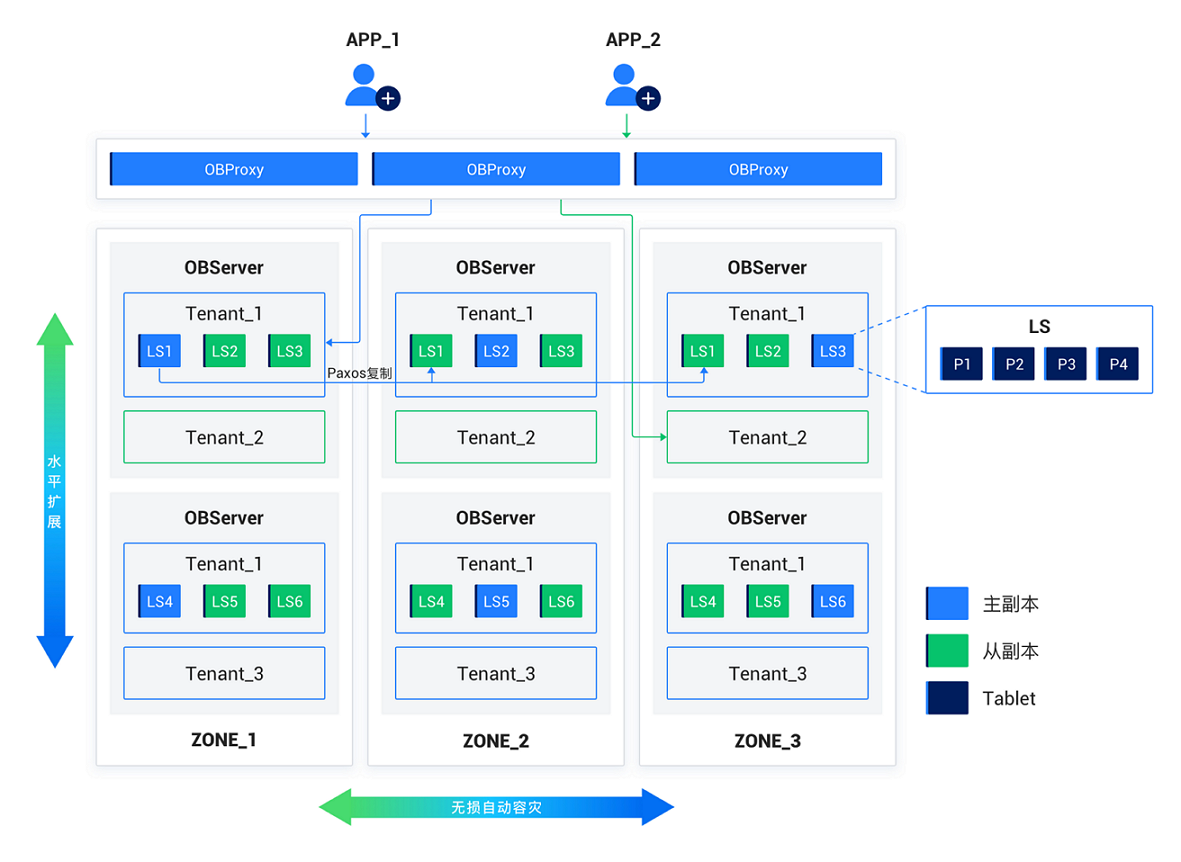
- 可用区(ZONE):一个逻辑概念,表示集群内具有相似硬件可用性的一组节点(可以是同一个机架、同一个交换机甚至同一个数据中心等),每个可用区具有数据中心(IDC) 和地域(region)两个属性
- 分片(Partition):一个表的数据按照某种划分规则水平拆分为多个分片,每个分片叫做一个表分区,某行的数据属于且只属于一个分区,一个表的分区可以分布在一个可用区内的多个节点上,每个物理分区有一个用于存储数据的存储层对象,叫做 Tablet,用于存储有序的数据记录
- 三副本和一致性:主从副本基于 Multi-Paxos 进行同步,写主读所有,写的时候还需要写 Redo log 到日志流中,一个日志流负责其所在节点上的多个 Tablet
- 线程模型:集群的每个节点上会运行一个 observer 的服务进程,其内部包含多个操作系统线程,负责所在节点上分区数据的读取,也负责路由到本节点的 SQL 语句的解析和执行
OceanBase 存储架构
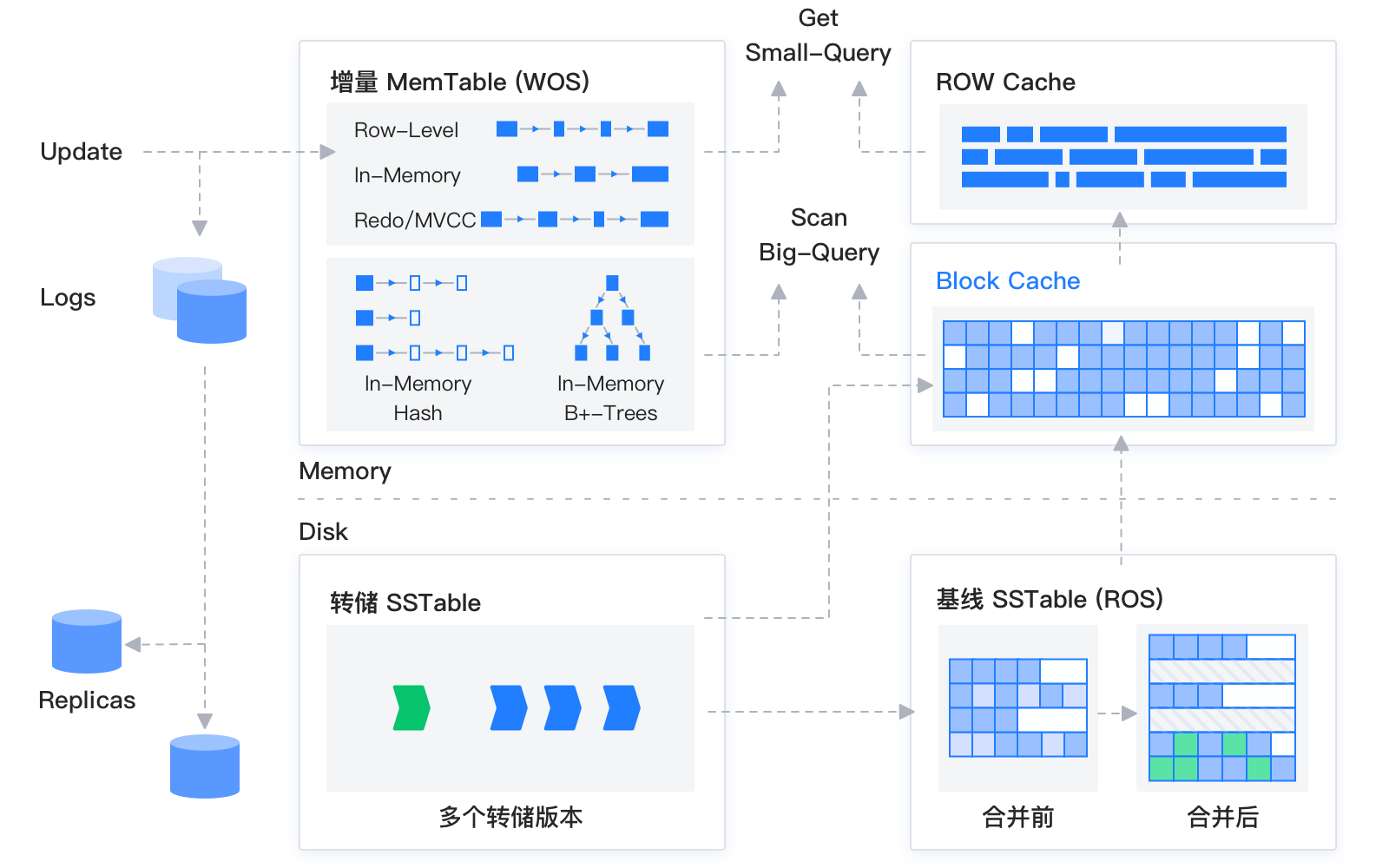
- 只读的静态基线数据(SSTable,硬盘)和可读写的动态增量数据(MemTable,内存,使用 B 树和哈希表索引)
- 在内存实现了 Block Cache 和 Row Cache,使用布隆过滤器来避免对基线数据的随机读
- OB 借鉴了传统数据库的分页,把数据文件按照 2 MB 为基本粒度切分为宏块,每个宏块继续切分出多个变长的微块,合并时会基于宏块的力度进行重用,没有更新的数据宏块不会被打开读取,尽可能减少写放大
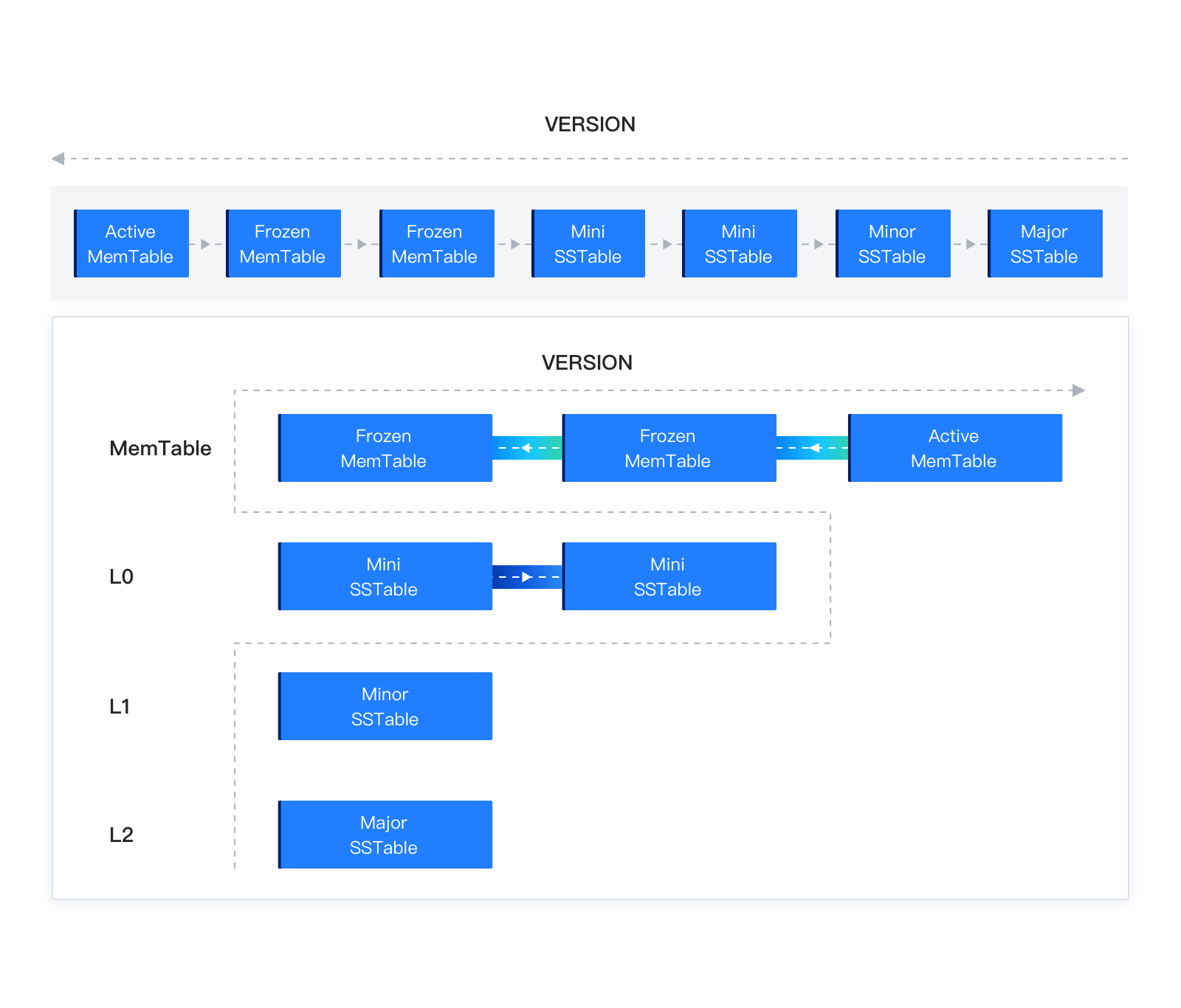
| 转储(Mini Compaction) | 转储(Minor Compaction) | 合并(Major Compaction) |
|---|---|---|
| 分区或租户级别,只是 MemTable 的物化 | 分区级别 | 租户级别,产生一个租户级快照 |
| 每个 OBServer 节点的每个租户独立决定自己 MemTable 的冻结操作,主备分区不保持一致 | 每个分区根据当前 SSTable 数量来执行分区内的 Minor Compaction | 租户所有分区一起做 MemTable 的冻结操作,要求主备分区保持一致,在合并时会对数据进行一致性校验。 |
| 可能包含多个不同版本的数据行 | 可能包含多个不同版本的数据行 | 只包含快照点的版本行 |
| 将一个或多个 MemTable 持久化为 SSTable | 只与相同大版本的 Minor SSTable 合并,产生新的 Minor SSTable,所以只包含增量数据,最终被删除的行需要特殊标记。 | 合并会把当前大版本的 SSTable 和 MemTable 与前一个大版本的全量静态数据进行合并,产生新的全量数据。 |
OBKV 简介
OBKV 是构建在 OceanBase 分布式存储引擎之上的 NoSQL 产品系列,目前支持 OBKV-Table、OBKV-HBase、OBKV-Redis 三种产品形态,原生继承了 OceanBase 的高性能、事务、分布式、多租户、高可靠的基础能力。此外,OceanBase 的工具体系(比如 OCP、OMS、CDC 等)也原生支持 OBKV,运维 OBKV 的各个产品形态和运维 OceanBase 的 SQL 集群完全一样。OBKV 可以帮助企业统一技术栈,在满足业务对多模 NoSQL 数据库诉求的同时,减少企业在数据库运维上的复杂度。